19 BÀI VỀ CHỮ VIỆT THỜI CÔNG NGHỆ SỐ
Tác giả: Long Ngo
Vài nét về Thạc sĩ Ngô Hoàng Đại
Long (Long Ngo)
Hiện là Nghiên
cứu viên tại Phân hiệu Đại học Quốc gia-TP.HCM tại tỉnh Bến Tre, có nhiều công trình khoa học – được công bố trên Scopus & WoS - liên quan
đến hướng
nghiên cứu của mình về Địa lý ngôn ngữ,
nhất là các Ứng dụng
của xử lý ngôn ngữ
tự nhiên trong GIScience.

1.
Chữ VN Song Song 4.0 (Cvnss4.0)
2.
Cvnss4.0 - Phát triển như thế nào?
3.
Vì sao Cvnss4.0 bị hiểu lầm?
4.
Có bao nhiêu chữ biến thể từ chữ Việt truyền
thống hiện nay?
5.
Kỳ 1. Ký sự bộ gõ tiếng
Việt - Sự xuất
hiện của “VIQR”
6.
Kỳ 2. Ký sự bộ gõ tiếng Việt - Đi tìm một
tiêu chuẩn thống nhất (?)
7.
Cvnss4.0 trong bối cảnh cách mạng công nghệ 4.0
8.
Cvnss4.0 về mặt ngôn ngữ
9.
Cvnss4.0 - Thuộc
nhóm các ngôn ngữ IAL?
10.
Chữ Quốc Ngữ
trong tiến trình lịch sử dân tộc
11.
Cvnss4.0 trong hành trình tìm
tiếng nói đồng thuận
12.
Tiện ích nhỏ từ Cvnss4.0 mang lại
13.
Cvnss4.0 dưới
góc nhìn mã hóa
14.
Những chữ cái dùng “lậu”
15.
Vũ điệu
của những con chữ
16.
Cvnss4.0 từ “phát kiến” đến sự hình thành giả
thuyết cho bộ chữ Bila
17.
Giá trị tiếng Việt qua các minh chứng. Thêm góc nhìn
từ Cvnss4.0
18.
Chữ Việt cổ
qua lăng kính Cvnss4.0
19.
Mạn đàm về thanh điệu trong tiếng Việt từ quá khứ đến
tương lai
Giới thiệu: Từ ngày
14-8-2022 đến ngày
13-5-2023, Thạc sĩ
Long Ngo đăng trên
Phây búc (Facebook) ở
nhóm “Tôi Yêu Chữ Việt 4.0” một loạt hơn 20 bài ngắn dài liên quan đến
chữ Việt thời
công nghệ số, như về: Chữ Quốc Ngữ, bộ gõ tiếng Việt, Chữ VN Song Song 4.0, v.v …
Sau đây
là 19 bài trong loạt bài trên.
BÀI 1: CHỮ VN SONG SONG 4.0
(ngày 14-8-2022)
Tôi có
vài chia sẻ về chữ VN Song Song 4.0 (Cvnss4.0) dưới
góc nhìn cá nhân và
công việc của mình. Hy vọng quý ACE có thể phát
triển thêm.
1. Cvnss4.0 có phải là bộ
gõ tiếng Việt với các kiểu
gõ khác nhau.
Hiện Việt Nam có
hơn 10 bộ gõ tiếng Việt khác nhau. Như vậy, Cvnss4.0 có thể sẽ phát triển thành một bộ gõ tiếng
Việt hay nói đúng
hơn Cvnss4.0 vẫn
có nhiều lợi thế và tính ưu
việt trong việc phát triển này. Đơn cử hiện nay, trên các điện thoại thông minh việc gõ chữ có
dấu là rất hạn chế, chưa kể kiểu chữ Xiteen viết sai be bét nhưng vẫn được cộng đồng các bạn trẻ
dùng. Liệu lâu dần, có mất
đi sự giàu đẹp của tiếng Việt không?
Cvnss4.0 ra đời
có thể sẽ giải quyết bài toán này bởi
tính nguyên tắc và quy
luật đã được thiết lập ngay từ đầu làm cơ sở
cho việc xây dựng bộ gõ tiếng
Việt tối ưu
hơn.
2. Cvnss4.0 có thể thay thế cả Mã Morse quốc tế mã hóa
26 chữ cái tiếng Anh từ A đến Z để giao tiếp đặc biệt dành cho người
Việt. Tại sao không chứ? Ví dụ: truyền
tải tín hiệu thông qua Cvnss4.0, người phát tín hiệu và người nhận tín hiệu sẽ dễ dàng hiểu
được câu nói ấy bởi
âm thanh phát ra từ
định ước
Cvnss4.0 dựa trên Mã Morse. Trong một số ngành, lĩnh vực nhất định việc truyền tín dựa trên
“chữ có dấu” sẽ tốn kém và
mất thời gian.
3.Chữ Braille được
du nhập vào nước ta và được Việt hóa
từ năm 1898. Chữ Braille được
biểu diễn trong một ô hình chữ nhật đặt đứng gồm các chấm nổi, có thể
nhận biết khi sờ bằng
đầu ngón tay. Nhưng có ai từng chứng kiến việc dùng các chữ này
khó khăn thế nào khi
bỏ dấu chưa? Nếu thông qua Cvnss4.0 thì việc cải tiếng Chữ Braille cho người khiếm thị tại sao không
chứ?
4. Ngôn ngữ
lập trình không dựa trên tiếng Anh, tại sao không
chứ? Nếu ta dùng Cvnss4.0 cho một ngôn ngữ lập trình thì cũng
đáng tự hào chứ? Ta xem trường hợp của Python từ Hà Lan, Ruby từ Nhật
Bản và Lua từ Brazil…
Tôi vẫn
ủng hộ nhóm tác giả
và đề cao sự sáng
tạo cũng như tìm kiếm
các cá nhân
phát triển thêm Cvnss4.0 trên nhiều phương diện khác nhau để Cvnss4.0 trở nên thông
dụng. Tôi viết bài này là dựa
trên cá nhân
quan sát một thời gian dài và
không dựa trên bất cứ tài trợ
nào.
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/814720146608768/
-------------------
BÀI 2: CHỮ
VN SONG SONG 4.0 - PHÁT TRIỂN THẾ NÀO?
(ngày 15-8-2022)
Tôi có
vài ý kiến chia sẻ về chữ VN Song Song 4.0
(Cvnss4.0) dưới góc
nhìn cá nhân
có thể làm nhóm tác
giả “không vui” nhưng hy vọng đó
là cách giúp
cho Cvnss4.0 phát triển thêm:
1. Để am hiểu một chữ viết mới như Cvnss4.0 cần có thời
gian để mọi người cảm nhận thông qua các giá
trị tự thân nó mang
lại, bao gồm:
(i) Công bố
quốc tế về Cvnss4.0 trong các bài báo
khoa học về ngôn ngữ và NLP-Natural Language Processing;
(ii) Thông qua các ứng dụng từ Cvnss4.0 mang lại, cụ thể là các
ứng dụng IT để mọi người thấy các tính năng
của nó mang lại;
(iii) Cvnss4.0 nên chia ra nhiều nhánh phát triển
và nâng lên
một tầm cao mới. Lý do, nhóm tác
giả hiện không thể phát triển nếu thiếu sự chung tay của một
nhóm người hoặc một tổ chức về Cvnss4.0. Điều
đó, đứa con
tinh thần Cvnss4.0, nhóm tác giả
phải xa dần nó để
cho nó (Cvnss4.0) lớn và trưởng
thành hơn. (tức có nghĩa
là về mặc bản quyền, Cvnss4.0 phải trở thành “ngôn ngữ mở” hay nói khác đi chấp
nhận nó trở thành tài sản chung
của cả dân tộc Việt Nam.
(iv) Việc chia sẻ thông tin và tranh luận
từ các group diễn đàn cũng tốt. Nhưng theo tôi không nên
tốn nhiều thời gian vào việc tranh luận vô bổ, chả
giải quyết được gì, càng làm mọi
thứ trở nên xấu đi.
Thay vào đó, xây dựng lực lượng các team nhỏ với các chuyên
môn khác nhau và các
chuyên ngành khác nhau cùng
nhau xây dựng và phát
triển. Nó sẽ hình thành
một diễn đàn riêng và xài Cvnss4.0 bắt buộc trong diễn đàn ấy.
Góc nhìn
của tôi có thể chưa
đúng nhưng nếu là tôi
Cvnss4.0 sẽ phát triển theo chiều kích vào các mảng
hẹp của ngôn ngữ từ đó nâng cao vị
thế của
Cvnss4.0. Chưa bao giờ
tôi từ bỏ chữ viết tiếng Việt
nhưng nếu có Cvnss4.0 thì đó sẽ làm cho công
việc và tiếng nói them giàu đẹp và phong phú
hơn.
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/815146673232782/
BÀI 3: VÌ SAO CHỮ CVNSS4.0
BỊ HIỂU NHẦM?
(ngày 16-8-2022)
- Thay đổi chữ viết Tiếng Việt
truyền thống
(hiện hữu),
mặc dù nhóm tác giả
có nhắc đến sẽ sử dụng song song (Cvnss4.0) và không ảnh hưởng đến
Chữ Quốc Ngữ
(chữ tiếng
Việt) hiện nay. Tuy nhiên, mọi người vẫn không hiểu hoặc nhóm tác giả chưa lý giải rõ tính hữu ích của Cvnss4.0 như thế nào?
- Mặc dù, nhóm tác
giả đã nhận được
giấy chứng
nhận bản quyền số 1850/2020/QTG
từ Cục Bản quyền tác giả thuộc Bộ
Văn hóa, Thể
thao và Du lịch (VH-TT-DL) cho công trình nghiên cứu chữ viết của mình. Tuy nhiên, việc thiếu đi các công bố
khoa học về
nó đã làm cho dư
luận ngờ vực về sự "cải tiến" của
Cvnss4.0, thậm chí
ngờ vực là "cải lùi"
- Cvnss4.0 chưa thể biểu hiện được tính biểu âm, biểu tượng mà chỉ là biểu lý và biểu
nghĩa. Chính vì vậy, mọi người sẽ khó chấp nhận nếu tính "biểu âm, biểu tượng"
là gì trong chữ viết? Cho nên, người đọc
lần đọc
tiếp nhận sẽ khó chấp nhận.
- Ở Nhật
bản có các loại chữ tiếng Nhật:
Hiragana, Katakana, Kanji và Romaji. Tuy nhiên, không phải người
Nhật nào cũng
rành. Ở Nhật còn
có một kiểu chữ đó là Ro-maji này dùng
để phiên âm các loại
chữ chính trong tiếng Nhật
như Kanji, Hiragana, Katakana để giúp người nước
ngoai thuận lợi hơn khi học tiếng Nhật. Điều
này khá tương tự như Cvnss4.0. Khi các bạn sử dụng bàn phím điện thoại tiếng Nhật
cũng nên chọn Japanese- Ro-maji
để việc
gõ chữ được quen tay giống tiếng Việt hơn.
Cvnss4.0 sẽ khó chấp nhận nếu đó là người Việt,
mà phải hướng đến
đối tượng
khác.
Vd: chuyển
các chữ dân tộc qua Cvnss4.0 rồi về lại chữ Việt truyền thống.
Trường hợp, chữ
Khmer (អក្សរខ្មែរ)
-> Cvnss4.0 -> chữ Việt.
Rất mong nhóm tác giả
có những giải pháp phát triển chữ Cvnss4.0 theo cách tiếp cận mới.
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/815921423155307/
-------------------
BÀI 4: CÓ
BAO NHIÊU CHỮ BIẾN THỂ TỪ CHỮ VIỆT TRUYỀN
THỐNG HIỆN NAY?
(ngày 18-8-2022)
- Chữ
Việt nhanh (chữ
Latinh) (viết tốc ký);
- Chữ VN
song song 4.0 (chữ
Latinh)
- Chữ
Việt không dấu
(dùng trong tin nhắn)
- Chữ Xiteen (chữ Latinh)
- Chữ phiên âm tiếng
Việt (Nghị định
30/2020/NĐ-CP) (chữ Latinh)
- 27 bộ chữ
viết phiên âm từ tiếng dân tộc qua tiếng
Việt (chữ Latinh).
- Chữ
Braille (chữ nổi)
dành cho người mù đã Việt hóa.
.....
Chữ Việt là bộ chữ
viết mà người Việt dùng để viết ngôn ngữ mẹ đẻ là tiếng Việt, từ quá khứ
đến hiện tại. Để ghi chép tiếng
Việt người Việt đã kết hợp cả chữ Hán với chữ Nôm lại,
và Chữ Quốc Ngữ (chữ Latinh). Và hiện
nay là Chữ Quốc
Ngữ trở nên thông dụng
và phổ biến. Chữ VN song song 4.0 không thể cạnh tranh hay thậm chí là thay
thế.
Chữ VN song song 4.0 là một
sự sáng tạo nhưng để chữ này làm đòn
bẩy tôi thiết nghĩ chúng ta cần có hướng đi riêng nhất
là trong mảng CNTT. Có thể tôi sai,
rất mong quý vị đóng góp thêm.
Long
Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/816997589714357/
-------------------
BÀI 5: KỲ
1. KÝ SỰ BỘ GÕ TIẾNG VIỆT - SỰ XUẤT HIỆN
CỦA "VIQR"
(ngày 24-8-2022)
Sau
năm 1975, có một làn sóng
người Việt Nam di cư đến Bắc Mỹ, châu Âu, Hồng Kông, Trung
Quốc và Úc. Tại Hoa Kỳ, dân số nhập cư Việt Nam trước đó chỉ tầm vài nghìn người
đến năm
1980 đã tăng lên thành 245.025 người. Đến năm 1990, con số này tăng gấp
đôi thành 593.213 và đến năm 2000 đã lên đến 1.122.528. Xa rời đất
mẹ và chịu sự lề hoá nơi
đất khách quê người, những người
Việt tha hương
luôn khát khao được hàn gắn sợi dây cội nguồn
và văn hoá bị đứt
gãy. Tiếng Việt
lúc này là
phương tiện
kết nối cụ thể nhất mà như
tác giả Anh Trần đã dẫn chứng trong Giáo dục Ngôn ngữ Việt Nam tại Hoa Kỳ rằng ít năm
sau 1975 có một sự tăng trưởng đột biến số lượng các trường dạy tiếng Việt
ở Hoa Kỳ.
Những nỗ lực duy trì kết
nối với quê nhà qua ngôn
ngữ diễn ra trong thời
điểm nhiều
có tiến bộ công nghệ.
Ngành công nghiệp máy tính chuyển dần từ máy tính lớn
sang máy vi tính cá nhân. IBM đã
phát hành mẫu máy tính
gia đình đầu tiên vào năm 1977 với cái tên
Altair 8800. Đến năm
1981, hãng bắt đầu sản xuất hàng loại máy IBM-PC, tương tự với máy tính
bàn hiện đại. Máy tính dần dần trở thành một thiết bị ngày một riêng tư và
cá nhân hơn.
Cộng đồng Việt kiều
ở Hoa Kỳ được
tiếp xúc với những tiến bộ máy tính này
khá sớm. Nguyên nhân là do vào
những năm 1990, có số lượng
lớn dân nhập cư người Việt đặc
biệt là phụ nữ giữ vị trí là những
kỹ thuật viên sơ cấp
ở Thung lũng Silicon, và
sau này là
kỹ sư trong lĩnh vực Công nghệ Thông
tin. Người Việt cũng
thuộc nhóm những người tiên phong về
ngành này ở Úc. Một ví
dụ có thể kể đến đó là chính các
bạn sinh viên tại trường Đại học Quốc gia Úc đã hoàn
thành dự án mang kết
nối internet đến
Việt Nam.
Trong
cuốn sách Transnationalizing Vietnam: Community, Culture, and Politics in the
Diaspora, Kiều Linh Caroline Valverde nói về lập
trình viên máy tính Tín
Lê, thành viên của một nhóm các nhà
khoa học máy tính người Mỹ gốc Việt có chuyên về
thiết lập liên kết qua mạng diện rộng. Năm 1986, nhóm này đã
kiến tạo một danh sách email lấy tên là Vietnet,
nhằm kết nối các cộng
đồng người
Việt hải ngoại
thông qua giao tiếp điện tử. Trong một lần phỏng vấn với Kiều
Linh Caroline, Tín Lê chia sẻ:
“Thật khó để kết nối với nhau, đặc biệt là ở những khu vực có ít
người Việt cư
trú. Chúng tôi ai cũng mong muốn được làm quen và
trò chuyện cùng nhau.”
Các
quản trị viên của Vietnet sau đó
đã chuyển danh sách email này đến một nhóm tin Usenet, một diễn đàn thảo luận tên là soc.culture.vietnamese
(SCV). Danh sách email của
Vietnet và SCV đều có trước internet vì cả hai đều
dựa vào các mạng lưới nhỏ – tiền thân của mạng lưới toàn cầu. Kho lưu trữ của Google về các cuộc
thảo luận nhóm tin cho thấy
SCV ra đời từ rất sớm – tháng Tư năm 1991. Ta có thể tìm
thấy mọi thông tin liên quan đến Việt
Nam từ thi ca, lời bài hát,
công thức nấu ăn, quảng cáo, tìm kiếm người thân, thông báo dự
án học tập, cho đến các cuộc thảo luận về các vấn đề
lớn hơn trên diễn đàn này.
Máy tính thời kỳ đó chỉ hỗ trợ tiêu chuẩn mã hóa ký tự
ASCII (viết tắt
của Mã tiêu chuẩn Mỹ trong Trao đổi Thông tin). Bộ
mã chỉ thể hiện bảng chữ cái tiếng Anh trên máy tính
và không bao gồm dấu phụ. Để liên lạc với nhau trong nhóm tin, các thành viên
Vietnet và SCV đã sử dụng một bộ quy tắc
cho phép các thành viên
viết tiếng
Việt bằng cách sử dụng các ký tự
có sẵn trong ASCII để biểu thị dấu phụ của tiếng Việt.
Bộ này bao gồm (. + ^? và '). Các quy tắc thường
được gọi
chung là quy ước Vietnet, quy ước
SCV hoặc quy ước VIQR (là viết tắt của Vietnamese Quoted-Readable). Các quy ước VIQR đã trở thành tiêu chuẩn
mà nhiều công dân trực
tuyến Việt Nam trong
thời hoàng kim của các
nhóm tin và diễn đàn tin dùng, và vẫn
còn được nhiều người sử dụng cho đến tận ngày nay.

Ảnh chụp lại từ Một
bài đăng trên Usenet liệt kê một số
tên tiếng Việt nhưng nghe như những từ mang ý tứ xúc phạm
trong tiếng Anh để các bậc phụ huynh lưu tâm khi đặt
tên cho con tránh bị người Mỹ chế giễu. Ảnh chụp màn hình qua Google Group.
DÒNG CHẢY Ồ ẠT CỦA CÁC
GIẢI PHÁP CÔNG NGHỆ
Các quy ước VIQR dù tiện lợi
nhưng suy cho cùng cũng
chỉ là một giải pháp tạm thời vì những
người chưa thạo vẫn không đọc được nội
dung tiếng Việt này.
Nhu cầu thiết lập một mã chuẩn cho các ký
tự tiếng
Việt sử dụng
trên các trang web và các
phông chữ vẫn luôn hiện hữu. Vì thế, vào
cuối những năm 1980 và đầu những năm 1990, đã có rất nhiều
phần mềm, bộ mã hóa
ký tự và phông chữ
tiếng Việt xâm nhập vào thế giới mạng. Có một vài giải
pháp khá hữu hiệu, thế nhưng phần lớn lại đề ra một nan đề mới. Như
Kim An Lieberman giải thích
trong Asian America.Net:
Ethnicity, Nationalism, and Cyberspace, "Vấn đề không phải là làm thế
nào để đưa tiếng
Việt lên internet, mà
là sử dụng phiên bản tiếng Việt nào."
Thời gian này xuất
hiện một tiêu chuẩn mã hóa, đồng
thời cũng là một phương
cách nhập liệu phổ biến: tiêu chuẩn VNI. VNI được
phát triển bởi ông Hồ Thanh Việt, một kỹ sư phần mềm người
Việt sinh sống tại Westminster. Năm
1987, ông Việt đề
xuất sử dụng các phím số để
biểu thị dấu phụ.
Phương thức nhập
liệu này được ông
Việt và Công ty Phần
mềm VNI phổ cập và biến
thành một sản phẩm dưới dạng một chương trình xử lý phông chữ và văn bản, thiết
kế cho hệ điều hành MS-DOS.
Từ đây, VNI trở thành tiêu chuẩn
cho in ấn ma trận điểm, giúp cải thiện hình thức trình bày của các
tờ báo tiếng Việt ở Mỹ.
VNI thậm chí còn được
Microsoft áp dụng vào hệ điều
hành Windows 95 vào những năm 1990. Tuy nhiên, VNI Software sau đó đã kiện Microsoft về việc sử dụng trái phép, buộc gã khổng lồ công nghệ
này phải loại xoá bộ gõ này
khỏi hệ điều hành của họ. Ngày nay, tiêu chuẩn VNI được
dạy trong sách giáo khoa của bộ môn tin học, và vẫn được
nhiều người
sử dụng ở
Việt Nam.
Cũng trong khoảng thời gian này Hiệp hội Unicode ra đời. Hiệp hội được thành lập vào năm 1987 tại Thung lũng Silicon
với các thành viên làm
việc cho nhiều công ty công nghệ như Apple, Xerox, Sun microsystems, IBM và Microsoft. Hiệp hội Unicode mong muốn
đề ra một tiêu chuẩn chung để mã
hóa và hiển
thị mọi ngôn ngữ bao gồm cả tiếng Việt. Hiệp
hội đã mở rộng tiêu chuẩn 8 bit thông dụng
trong việc mã hóa ký
tự bấy giờ thành bộ ký tự
16 bit để tăng
số lượng ký tự có
thể mang chứa.
Đối với tiếng Việt,
kế hoạch ban đầu của hiệp hội này là để
gán mã cho
từng dấu phụ, thay vì gán mã
cho một tổ hợp sẵn. Lý do là vì Unicode muốn tiết kiệm dung lượng và tránh phải mã hóa những
ký tự có thể được
tạo ra bằng cách kết các ký
tự đã được gán mã. Tuy nhiên, trong quá trình
thực hiện
Unicode lại gặp
phải một số vấn đề.
Theo một ghi chú của Tập đoàn phi lợi nhuận Viet-Std thành lập với mục đích chuẩn hóa tiếng Việt trên máy tính,
"Việc sử dụng nhiều dấu phụ trong các văn
bản tiếng
Việt dẫn đến
nhu cầu tạo ra một
bàn phím nhập liệu không cần thêm phím tắt
đặc biệt nào để ‘soạn’ các chữ cái có
dấu." Tiến sĩ
Ngô Đình Học, một
trong những thành viên của
Viet-Std, cho rằng góc nhìn này
khá là không
công bằng bởi lẽ người Pháp và người Đức lại
được hưởng
đặc quyền có mọi ký
tự được
mã hóa sẵn
trong bộ Unicode.
Tập đoàn Viet-Std đã gửi đơn khiếu nại đến Unicode để
xem xét lại
việc này nhưng bị từ chối với lý do ngôn ngữ tiếng Việt không có một hệ
thống mã hóa ký tự
thống nhất, do đó, không cần phải đảm bảo khả năng tương thích như các ngôn
ngữ gốc La-tinh khác. Không
chấp nhận lập luận của Unicode, Tập đoàn Viet-Std đã phát triển tiêu chuẩn mã hóa ký
tự VISCII (Mã Tiêu chuẩn của Việt Nam để
Trao đổi Thông tin) vào
năm 1992. VISCII dựa
trên nền tảng của bộ ký tự
ASCII đã được
chỉnh đổi,
trong đó các ký tự
“dễ xử" nhất trong bộ ASCII gốc được thay thế bằng các dấu phụ
tiếng Việt.
Mãi đến năm 1993
Unicode mới đồng
ý mã hóa mọi ký tự
thuộc tiếng
Việt. Từ đó
trở đi, nhiều quy ước đánh máy hơn đã
xâm nhập vào thế giới
mạng. Vào năm 1993, tổ chức phi lợi nhuận Vietnam Professionals Society (VPS) phát hành phần mềm phương thức nhập liệu VPSKey của riêng mình, thiết kế cho hệ
điều hành
Windows 3.1. Cũng trong
năm đó, Bộ Khoa học, Công nghệ và Môi
trường của
Việt Nam (nay là Bộ
Khoa học và Công nghệ) đã ban hành TCVN 5712 – một tiêu chuẩn mã hoá ký
tự 8-bit toàn quốc cho tiếng Việt. Mã hóa ký tự
TCVN 5712 được gọi
là VSCII (Mã Trao đổi Thông tin Tiêu chuẩn của Việt
Nam) và bao gồm ba phiên bản:
VN1, VN2 và VN3. Bộ đầu tiên là bộ ASCII đã được điều chỉnh, hai bộ còn
lại sử dụng ASCII mở rộng. TCVN 5712 khi đó được sử dụng rộng rãi ở miền bắc nước ta.
Các
trang web cuối cùng cũng có thể hiển
thị đúng tiếng Việt và người dùng có thể viết
tiếng Việt trên
web nếu đầu
ra và đầu
vào tương thích với nhau.
Tuy
nhiên, việc
gõ và đọc
tiếng Việt trên
máy tính vẫn là một
vấn đề đau đầu do có quá nhiều
giải pháp – với mỗi giải pháp cho phép từng
trang web sử dụng bảng mã và phông
chữ không tương thích với nhau. Do đó, những người dùng không được trang bị các công cụ
phù hợp vẫn không thể đọc và viết tiếng
Việt một cách dễ dàng.
(Xem
tiếp kỳ
2). KỲ 2. KÝ SỰ BỘ GÕ TIẾNG VIỆT -
ĐI TÌM MỘT TIÊU CHUẨN THỐNG NHẤT (?)
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/821130762634373/
-------------------
BÀI 6: KỲ 2. KÝ SỰ BỘ
GÕ TIẾNG VIỆT - ĐI TÌM MỘT TIÊU CHUẨN THỐNG
NHẤT (?)
(ngày 25-8-2022)
Nhiều phần mềm và bộ xử
lý văn bản vẫn tiếp tục sử dụng mã hóa ký
tự tiếng Việt
7 bit và 8 bit trước khi Microsoft
Windows đưa mã hóa Unicode cho tiếng Việt vào phiên bản 2000.
WinVNkey là chương trình máy tính
đầu tiên cho phép người
dùng gõ tiếng
Việt trên Windows 3.0 – phiên
bản đầu tiên của hệ điều hành Windows sau MS-DOS. TriChlor – một nhóm phi lợi nhuận ủng hộ việc lấy VISCII làm tiêu chuẩn sử dụng thống nhất, đã thiết kế và cung
cấp WinVNKey miễn phí cho người dùng. Vào năm
2000, khi nhận ra tiềm năng
phát triển của Unicode, WinVNkey bắt đầu hỗ trợ tiêu chuẩn mã hoá này.
Về sau tác giả
Ngô Đình Học, khi
ấy đang làm việc với Unicode và thiết kế trình điều khiển bàn phím tiếng Việt cho Macintosh (là một dòng sản phẩm máy tính cá
nhân được thiết kế, phát triển, và đưa ra thị trường
bởi Apple Inc), đã
tiếp quản dự án này.
Chương trình này trở thành
một phần mềm cho phép
nhập liệu đa ngữ là kênh dẫn
cho hơn 30 ngôn ngữ quốc tế cũng từng gặp phải khúc mắc khi đưa vào máy tính.
Chương trình cũng hỗ trợ ký tự
chữ Nôm và ngôn ngữ
dân tộc thiểu số Việt
Nam.
Ngang
tài ngang sức với WinVNKey phải kể đến hệ thống Vietkey khá phổ
biến. Vietkey được phát triển vào năm 1991 và phát hành vào
năm 1997 bởi Vietkey Group, một công ty có trụ
sở tại
Việt Nam thành lập
bởi Đặng Minh Tuấn – một kỹ sư trẻ của Bộ Quốc phòng thời đó. Ban đầu, Vietkey là một
phần mềm miễn phí rồi sau đó
được thương
mại hoá cùng với các sản phẩm
khác của công ty. Vietkey hỗ trợ tiếng Việt, tiếng
Anh, tiếng Pháp, tiếng
Đức và tiếng
Nga và thậm chí còn có
cả một phiên bản tương thích với hệ điều hành Linux. Cũng giống với đội ngũ đằng sau WinVNKey, Đặng
Minh Tuấn ủng hộ
việc tạo dựng một tiêu chuẩn mã hóa ký
tự phổ cập để gõ tiếng Việt. Vào năm 1997,
Đặng Minh Tuấn và Vietkey đề xuất hỗ trợ Unicode, đến
năm 2000, họ đã điều chỉnh phần mềm này sao
cho chỉn chu hơn. Tuy nhiên, Vietkey vẫn có một yếu
điểm đối
với nhiều người: phần mềm này có
thu phí.
Phạm
Kim Long, lúc bấy giờ vẫn còn là một
sinh viên cao học tại
Prague, nhận thấy
nhu cầu cho một phần
mềm khác có thể truy
cập rộng rãi và có
thể hỗ trợ Unicode ngoài Vietkey. Ông Long đã có ý tưởng
phát triển phần mềm phương thức nhập liệu của riêng mình, và đã
cho phát hành Unikey vào
năm 2000. Bản rút gọn miễn
phí của phần mềm này hiện có mặt trên
khắp các máy tính ở Việt Nam. Ấp ủ ý tưởng
này từ năm 1991 khi ông và các
bạn cùng lớp tại Đại học Khoa học và Công nghệ Hà Nội thách đố nhau viết một chương trình đánh máy tiếng Việt nhẹ nhất bằng ngôn ngữ Assembly. Ông Long đã chiến thắng với một chương trình chỉ nặng 2 kilobyte được
gọi là LittleVNKey.
Tuy
nhiên, LittleVNKey không hỗ trợ Unicode. Năm 2000,
ông bắt tay thiết kế một chương trình nhập tiếng Việt
với hỗ trợ Unicode, sau khi xem các
thảo luận trực tuyến về việc Windows 2000 có thể hỗ
trợ nhiều ngôn ngữ trong đó có
tiếng Việt. Ông
đã dành hai ngày để
lập trình và phát hành
trực tuyến phiên bản đầu tiên của Unikey. Sau đó, ông đã
dành bốn tháng tiếp theo để nhận phản hồi và tinh
chỉnh phần mềm của mình. Năm 2006, thông qua một người bạn
Việt Kiều, Phạm Kim Long đã đồng ý để
Apple quyền tích hợp phần mềm trong hệ điều hành của mình. Unikey vẫn
là một phần mềm miễn phí và còn đang
hiện hành.
Mặc dù ông Long và
ông Tuấn là hai người được biết đến nhiều nhất trong hành trình cho
tiếng Việt tương
thích với máy tính hiện
đại, sự phát triển của công nghệ đánh máy đa dạng
hơn nhiều và phản ánh
nhu cầu văn hóa xã
hội và lịch sử của một nhóm người khao khát kết nối với thế giới và với chính
cộng đồng của họ.
Hiện nay đã có khá
nhiều bộ gõ tiếng việt cho máy tính Windows/Linux để hổ trợ chúng ta dễ dàng mỗi
khi cần nhập văn bản bằng Tiếng Việt trên Word,
Chat, … Các bộ gõ này được tồn tại ở các phiên bản
có phí và
miễn phí mà đôi khi
bạn sẽ cảm thấy rất khó khăn
trong để có thể chọn
cho mình bộ ứng dụng phù hợp như:
- GoTiengViet của tác giả Trần Kỳ Nam;
- VPSKeys do Hội
Chuyên gia Việt Nam;
- EVKey do Lâm Quang Minh phát triển;
- OpenKey của tác giả Mai Vũ Tuyên;
- TocKyVNKey là bộ gõ tiếng việt của tác giả VanTran;
- Bộ gõ Laban Key/Gboard/GoTiengViet trên các thiết
bị di động;
- ...
Tóm
lại, bộ gõ tiếng Việt là một chương
trình máy tính loại phần mềm hỗ trợ soạn thảo văn bản bằng tiếng Việt
trên máy tính, thường cần phải có font ký tự
Chữ Quốc Ngữ
đã được
cài đặt trong máy tính.
Các bộ gõ tiếng Việt khác nhau sẽ hỗ
trợ một hay nhiều bảng mã và kiểu
gõ. Mỗi bảng mã quy
định việc thể hiện font chữ khác nhau và mỗi
kiểu gõ quy định việc viết dấu bằng các tổ hợp
phím khác nhau. Mỗi bộ gõ điều
có ưu nhược khác nhau.
Nếu nhìn nhận dưới góc độ Ergonomics Cvnss4.0 cũng là một
kiểu gõ hỗ trợ soạn thảo văn bản bằng tiếng Việt
nhằm đặt tới sự tối ưu hóa về tốc
độ, linh hoạt hơn trên thiết bị Smartphone, tốc ký hóa khi
ghi biên bản. Việc sử dụng Cvnss4.0 không phải để thay thế cho Chữ
Quốc Ngữ (chữ
Việt truyền thống),
mà tôi nghĩ
Cvnss4.0 là thêm một giải pháp hữu ích về mặt
công nghệ trong cải thiện hoặc hỗ trợ bổ khuyết nhằm tăng tính ưu việt
hơn nữa việc biểu đạt tiếng nói của dân
tộc Việt trên trường quốc tế.
(Xem
tiếp kỳ
3). KỲ 3. CHỮ VN SONG SONG 4.0 (Cvnss4.0) TRONG
BỐI CẢNH CUỘC CMCN 4.0
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/821783012569148/
-------------------
BÀI 7: CHỮ VN SONG SONG 4.0 TRONG BỐI
CẢNH CÁCH MẠNG CÔNG NGHỆ 4.0
(ngày 1-9-2022)
1. Cơ
duyên đến
với Chữ
VN Song Song 4.0 (Cvnss4.0)
Những
đầu năm
2012 tôi tình cờ biết đến Dự
án chữ tốc ký (CTK) qua Phương
pháp mới gõ tắt chữ
tiếng Việt [1] của tác giả
TRẦN TƯ BÌNH2; hồi đi học khi làm các bản đồ
trên Arcview GIS3,
trong lúc thao tác “làm
nhãn hiển thị tên địa
danh” cho các bản đồ
thường gặp
rất nhiều khó khăn vì
chưa có chức năng hiển thị dấu của chữ tiếng Việt.
Dự án này đã được
giới thiệu từ rất lâu qua Tạp chí công nghệ
eChip4 – một tờ báo công
nghệ lớn vào thời kỳ internet mới
được phổ
cập ở Việt Nam. Sau này, tôi biết nhóm tác giả TRẦN TƯ BÌNH và KIỀU TRƯỜNG LÂM5 mà hai nhà
nghiên cứu này đã đề
xuất Dự án gồm 3 thành phần: Chữ Quốc Ngữ
hiện hành, Chữ Việt Nhanh và Ký hiệu dấu.
Như vậy, Cvnss4.0 gần
10 năm sau! nhóm tác giả
đã được
ghi nhận khi được cấp Bản
quyền6 và hoàn chỉnh hơn về Cvnss4.0.
Nếu khai thác và xử
lý tốt thì Cvnss4.0 sẽ
được ứng
dụng trong lĩnh vực máy tính rất
nhiều, nhất là trong bối
cảnh của Cuộc cách mạng công nghệ 4.0. Cvnss4.0 là hoàn toàn
không có dấu riêng biệt; không cần phần
mềm tiếng Việt;
nếu biết Chữ Quốc Ngữ
(CQN) thì việc
học Cvnss4.0 rất dễ bởi quy tắt
của nó khá đơn giản, dễ hiểu và học
nhanh.
2. Cvnss4.0 trong bối cảnh Cách mạng công nghệ 4.0 (CMCN
4.0)
Cuộc
cách mạng công nghệ 4.0 (CMCN 4.0) [2]
được hiểu
ngắn gọn như sau: CMCN lần 1: Cơ
khí hóa; CMCN lần 2: Điện
khí hóa; CMCN lần 3: Tự
động hóa và CMCN lần 4: Số hóa. Số hóa
(Digitization) là quá
trình chuyển đổi thông
tin trên giấy và các quy trình thủ
công thành định dạng
kỹ thuật số. Số
hóa có tầm quan trọng rất lớn đối với việc quản lý, khai thác, xử
lý, lưu trữ và truyền
dữ liệu.
Thí dụ: Ta lấy công nghệ OCR7 để số
hóa trong việc đọc text
(chữ) ở file ảnh, đây là một công cụ scan kỹ thuật số chuyên nhận dạng các ký tự,
chữ viết tay, hay chữ đánh máy để
truyền tải kỹ thuật số dưới nhiều dạng tài liệu khác nhau: hóa
đơn, hộ chiếu, danh thiếp, tài liệu, … Tuy nhiên! phụ thuộc vào độ rõ nét của ảnh dùng, xử lý dấu tiếng Việt, nhận
diện mẫu
chữ – khó khăn nhất vẫn là chữ viết tay. Cvnss4.0 được
nhóm tác giả thiết lập là hệ thống ký hiệu có quy tắc
– nó giống như hệ thống định lý toán học trong môi trường
máy tính – là “bước đệm” trung gian để chuyển hóa những giá trị của chữ tiếng Việt hiện tại chưa được tối ưu sang hệ thống quy ước xã hội ở thế giới thực.
3. Ứng
dụng Cvnss4.0 đang
hướng đến
Hiện
nay! bắt đầu
đã có nhiều ứng dụng được tạo ra từ Cvnss4.0 [3],
[4], [5]. Tuy nhiên! Cvnss4.0 có tiềm năng vấn rất lớn – nhất là trong môi trường tương tác giữa con người –
máy tính (Human-Computer
Interaction).
3.1 Ngôn ngữ trị liệu – luyện trí nhớ
- Thứ nhất:
Quá trình ghi nhớ từ
vựng, cụm từ và quy
tắc ngữ pháp đều thực hiện ở tế bào não
của bạn. Các bài tập thể
dục trí não từ Cvnss4.0 sẽ giúp rèn
luyện trí
nhớ tổng thể hàng ngày. Nhiều nghiên cứu đã chỉ ra rằng những
người học
song ngữ ít có nguy cơ
mắc bệnh
Alzheimer8 hơn. Nếu áp dụng Cvnss4.0 thì sẽ có
thể cải thiện trí nhớ đáng kể.
- Thứ hai:
Nhằm làm tăng khả năng nhớ của bộ não, nhiều nhà khoa học đã nghiên cứu và tìm
ra các phương
pháp ghi nhớ. Các phương pháp này hiện
nay được những
người tham gia cuộc thi trí nhớ
thế giới sử dụng thuần thục. Bất cứ ai cũng có thể
sở hữu trí nhớ gần
như hoàn hảo nhờ luyện tập phương pháp mã hóa. Nguyên tắc căn bản giúp con người tăng cường trí nhớ là mã hóa những chủ thể khó nhớ
(ví dụ như số điện thoại, tên người, công thức toán) thành những chủ thể dễ nhớ đối với não người (ví dụ như
hình ảnh, địa điểm, cảm xúc). Cvnss4.0 cũng được thiết kế dựa trên phương pháp mã hóa.
- Thứ ba: Cvnnss4.0 ước tính giảm được gần 30% thời gian gõ; với
những người
có các cơn
đau liên quan đến máy tính (bệnh RSI)9 thì
gần 30% là rất nhiều. Một giờ gõ phím liên
tục sẽ chỉ còn 40-45 phút, 5 giờ gõ phím liên
tục chỉ còn 3 giờ, v.v. Tất nhiên! con số 30% này cần được xác minh thêm
– và ngay cả như vậy – hiệu quả của nó với việc
giảm thiểu các vấn đề
về RSI cũng cần được khảo sát kỹ.
3.2 Ngôn ngữ ký hiệu
mật mã
Trong mật
mã học ta thấy việc “chuyển vị
Caesar” là một trong những kỹ thuật mã hóa đơn giản, phổ biến nhất và có
lịch sử lâu đời nhất. Đây là một dạng mật mã thay thế,
trong đó mỗi ký tự
trên văn
bản thô sẽ được thay bằng một ký tự
khác, có vị trí cách
nó một khoảng được
xác định trong bảng chữ cái; các quy tắc
thay thế chữ cái đơn trong bảng chữ cái tiếng Anh qua việc sử dụng 26 mật
mã Caesar10 với
các bước dịch chuyển từ 0 đến 25 – tương ứng từ chữ ‘a’ đến chữ ‘z’.
Nếu ai biết Chữ Quốc Ngữ
(chữ tiếng Việt) thì sau khi
học thêm Cvnss4.0 sẽ khá hữu
ích trong việc ứng dụng các mật mã dùng tiếng Việt hoàn toàn.
Thí
dụ: Mã
Capcha11 được máy tính tạo
ra để xác định tính “con người”,
chủ yếu là reCaptcha và noCaptcha. Khi phải dừng lại để xác minh mã
Captcha thì có rất nhiều người cảm thấy phiền phức nhất là người
Việt. Việc Cvnss4.0 được dùng trong việc xác định từ/cụm từ sẽ rất hữu ích vì việc
chuyển đổi
nhận dạng CQN-Cvnss4.0 –
và ngược lại – sẽ giúp ta chống lại việc spam, bảo vệ cho dữ liệu,
tính chân thực trong tương tác giữa người và máy tính.
Hay như! Private
Key hoặc Seed Phare là chiếc chìa khoá giúp
bạn truy cập vào cánh
cổng đó và tương tác với tài
sản của bạn trên ví điện tử. Những cụm từ – đôi khi trở
nên vô nghĩa
và bạn không nhớ chính xác – dẫn
đến mất luôn ví điện tử mà tài sản
của mình chứa trong đó. Do vậy! CQN-Cvnss4.0 –
và ngược lại – sẽ giúp bạn dễ nhớ nếu có lỡ
quên từ khóa bí mật.
3.3 Hỗ trợ cuộc sống cho người khiếm thị
Ngày
nay, việc áp dụng công nghệ OCR đã được tích hợp với công nghệ tổng hợp giọng nói (giọng máy) giúp máy có
khả năng đọc hiểu văn bản. Có thể thông
qua Cvnss4.0 để cải tiến chữ Braille12 cho người khiếm thị dùng được dễ dàng hơn.
Nói cách khác, văn bản không chỉ được phần
mềm máy tính giải mã, mà còn
được công cụ tổng hợp giọng nói đọc ra thành tiếng. Giọng nói vi tính hóa đã được ứng dụng vào việc đọc văn bản giúp người cao tuổi, người khiếm thính đọc sách, báo khiến cuộc sống của họ trở nên nhẹ
nhàng hơn; hoặc giúp nhân bản được chính giọng nói của mình trong các ứng
dụng để phục vụ cho các ngành
dịch vụ, truyền thông và tiếp thị
qua việc xử lý chuyển đổi ngôn ngữ và giọng
nói cá nhân.
3.4 Bảo tồn các văn bản
có giá trị
của các dân tộc
Tại
các bảo tàng, thư viện cổ hay các trung tâm
văn hóa lịch sử, người ta cần lưu trữ rất nhiều tài liệu, hồi ký, bản
thảo, …; các tài liệu này rất dễ
bị mối mọt theo thời gian. Quá trình lưu
trữ cần rất nhiều thời gian, công sức và không hề
đơn giản. Việc sắp xếp, lưu trữ hoặc tìm kiếm thủ công – với lượng văn bản giấy khổng lồ – là vô
cùng vất vả và tốn
nhiều nhân lực thực hiện. Tuy nhiên! Cvnss4.0 ra đời đã giúp giải
quyết bài toán đó một
cách đơn giản hơn thông qua việc chuyển đổi ngôn ngữ theo một quy chuẩn nhất định. Các văn bản, tài liệu quan trọng được chuyển
đổi từ dạng giấy sang file
mềm. Giúp việc lưu trữ và bảo
tồn nhiều di sản văn học/văn hóa của các
dân tộc trở nên dễ
dàng hơn. Trong số 27/54 dân tộc đã có chữ viết
thì cũng còn nhiều chữ viết chưa được mã hóa, chưa
có font chữ và bộ gõ
trên máy tính. Không có
chữ viết và font chữ thì rất khó
để bảo tồn và duy
trì ngôn ngữ đó, không quảng bá được trên Internet…
Cvnss4.0 sử dụng các ký tự Latin và sử dụng các tổ hợp ký tự
tiếng Việt nên
có thể tạo ra các
ký tự chữ viết cho ngôn ngữ
của các dân tộc, nhằm hạn chế tạo ra font chữ và bộ gõ
mới. Vấn đề này cần có sự
phối hợp giữa các nhà ngôn ngữ
học và chuyên gia xử
lý ngôn ngữ tự nhiên (natural language processing – NLP).
4. Cơ hội và thách
thức của
Cvnss4.0
4.1 Công nghệ
Blockchain
Blockchain hiện là một
công nghệ mới và sáng
tạo có tiềm năng thay đổi cách chúng ta tương
tác với internet và thế giới
kỹ thuật số. Ở dạng đơn giản nhất, Blockchain là
một cơ sở dữ liệu phân tán cho phép
thực hiện các giao dịch
an toàn, minh bạch và chống
giả mạo, có nghĩa là
thông tin có thể được lưu trữ trên blockchain và
được chia sẻ
trên một mạng máy tính mà không
cần cơ quan tổ chức
nào hoặc người trung gian bên thứ
3.
Ví
dụ: Hợp
đồng thông minh có thể được sử dụng để tự động thực hiện các thỏa thuận khi đáp ứng
các điều kiện nhất định, theo đó việc thực thi có thể diễn
ra mà không
cần bất kỳ sự can thiệp nào của người dùng. Trong suốt quá trình hoặc
tại các điểm tiếp xúc chính trong
quá trình triển khai, dữ liệu được lưu trữ trên blockchain cũng có thể
được phân tích bằng cách sử dụng
các thuật
toán NLP để
trích xuất những thông tin chi tiết có giá
trị. Cuối cùng, sử dụng Bockchain và NLP cùng nhau có thể
giúp bảo vệ quyền riêng tư.
4.2 Các ứng
dụng & Trường hợp sử dụng của việc kết nối blockchain-NLP từ
Cvnss4.0
4.2.1 Trên diện toàn cầu! để có cơ hội
có thể giúp lưu trữ
hồ sơ tốt hơn và xác minh
dữ liệu đáng tin cậy hơn, Blockchain giúp
tạo ra một hệ
thống lưu trữ hồ sơ an toàn và không bị
thao túng hoặc can thiệp. Ví dụ: Khi bạn tạo các hợp đồng thông minh Ethereum13, tức
là bạn đang viết một đoạn code
backend cho Dapp
(một mạng phi tập trung) bằng ngôn ngữ dành riêng cho Ethereum –
chẳng hạn như Solidity, Serpent, Vyper.0 có thể được
xem là ngôn ngữ riêng biệt trong hợp đồng thông minh (smart contract) của cấu trúc Dapp (frontend + smart contract backend).
4.2.2 Cvnss4.0 có
tiềm năng dành cho công
nghệ blockchain khi
được sử
dụng kết hợp trong NLP để tạo điều kiện cho các hợp
đồng thông minh bằng nội dung mà Cvnss4.0 đính kèm theo. Các
hợp đồng này sẽ cho
phép có tính
kinh tế theo quy mô
và tăng độ chính xác khi thực
hiện các thỏa thuận giữa nhiều bên mà giúp
đảm bảo rằng tài sản trí tuệ
được bảo
vệ và quản lý một
cách hợp lý.
4.2.3 Cuối cùng! Cvnss4.0 – được
ứng dụng trong cả công nghệ
blockchain và NLP – có
thể được
sử dụng kết hợp với nhau để tạo ra các ứng
dụng phi tập trung mới (dApps) có ngôn ngữ giao tiếp riêng. Các ứng dụng này – sẽ hoạt động ngoài tầm kiểm soát của bất kỳ bên nào hoặc
tổ chức nào – cung cấp
một cách để người
dùng kiểm soát dữ liệu
của họ. Nếu việc này không cẩn
trọng thì sẽ rất nguy hiểm vì Cvnss4.0 sẽ
bị kẻ xấu lợi dụng và bị xem như
ngôn ngữ trong môi trường Web xấu (Dark
web).
5. Kết luận
Có
thể thấy, vì Dự án Cvnss4.0 là một nỗ lực cải cách chữ viết của nhóm tác giả
– không dựa trên một lập luận ngôn ngữ học nào – mà dựa trên
những mong muốn
rất phi ngôn ngữ học tức là viết không dấu và tối ưu hóa bằng mọi giá, nên hóa ra
nó lại có thể là
một gợi
ý quan trọng cho các dự
án về công nghệ trong việc tận dụng sự cải cách chữ viết này, như tiếp tục cải tiến các bộ gõ như VNI hay Telex trên các thiết
bị di động
smarphone, trong một số trường hợp bắt buộc phải sử dụng tiếng
Việt không dấu và Cvnss4.0 trở
thành một lợi thế trên môi trường
máy tính. Việc thay đổi nhận
thức xã hội phải có thời gian
và lộ trình cụ thể cho từng dự án cộng đồng được ứng dụng cụ thể – từ đó, Cvnss4.0 sẽ
được phát huy tính hiệu
quả của nó.
CHÚ GIẢI
1: Long Ngo: Tên thật là NGÔ HOÀNG ĐẠI LONG – hiện đang là Nghiên cứu viên tại Phân hiệu Đại học Quốc gia-TP.HCM tại tỉnh
Bến Tre, có nhiều công trình khoa học – được công bố trên Scopus & WoS – liên quan đến hướng nghiên cứu của mình về Địa lý ngôn ngữ, nhất là các Ứng dụng của xử lý ngôn ngữ
tự nhiên (Natural
Language Processing – NLP) trong GIScience. (Facebook: Long Ngo – https://www.facebook.com/dailong0606 ,
Email: ngohoangdailong@gmail.com)

Hình: Lớp học cách xây dựng
các Ứng dụng phi tập trung từ Blockstack/Stack 2018
(Tác giả
Long Ngo mặc áo đỏ, ngồi ở
hàng ghế nhì)
2: TRẦN
TƯ BÌNH (1954, Đà Nẵng – hiện đang sống tại thành phố Sydney, Úc). Ông tốt nghiệp Trường
Cao đẳng Sư
phạm Tiểu Học
Đà Nẵng (năm 1974), Trường Đại học Tổng hợp Tp.HCM (năm 1977) chuyên ngành Ngữ Văn. Ông
là Giáo viên Văn tại Trường
Trung học Phổ thông cấp 3 Lý Thường
Kiệt, Tp.HCM (từ
1977-1980). Ở Úc, ông
làm việc tại Bưu
Điện Úc (từ 1982 đến nay
/2022) và dạy
thêm Việt ngữ ở Liên
Trường Văn hóa Việt Nam- Sydney (từ 1986-2016) vào cuối tuần. Ông phụ trách Quản
trị trang mạng Chữ
Việt Nhanh (http://chuvietnhanh.sf.net).

Hình: Cvnss4.0
& Đồng tác giả TRẦN TƯ BÌNH – KIỀU TRƯỜNG
LÂM
3: Arcview GIS là phần mềm thương mại (của
ESRI) về hệ
thống thông tin địa lý (GIS) giúp: Hiển thị các lớp bản
đồ dạng
vector, Tạo và thay đổi cơ sở dữ liệu của các đối
tượng địa
lý trên bản
đồ, Tạo các biểu đồ đơn giản dựa trên thuộc tính của các đối tượng trên bản đồ, Chuẩn bị các bản in ra giấy, Tạo các đoạn
chương trình phục vụ cho việc tự động hóa các thao
tác phần mềm, Đọc các định dạng ảnh khác, Tạo các hộp thoại (giao diện đồ họa người sử dụng), v.v…
4: Echip là tạp chí về
công nghệ thông tin ở Việt Nam, ra đời vào tháng 2/2003 trực thuộc Bộ Thông tin Truyền
thông. Echip có 3 loại báo tuần: e-CHÍP
Tin học trong tầm tay (phát hành vào
thứ 6), e-CHÍP Đọc
xong vọc liền (phát hành vào thứ
3), e-CHÍP Mobile (phát hành vào thứ
4). Sau 13 năm hoạt
động, Echip đã dừng phát hành báo giấy và chuyển sang hoạt động theo dạng báo điện tử từ ngày 1/5/2016.
5: KIỀU
TRƯỜNG LÂM (1986, Tuy Hòa, Phú Yên – hiện đang sống tại Hà Nội). Ông tốt nghiệp Cử nhân Quản
trị Kinh doanh –
chuyên ngành Marketing tại Trường Đại
học Kinh Tế, Huế và làm việc ở ngành Mậu dịch quốc tế. Ông và TRẦN TƯ BÌNH là Đồng tác giả Dự
án Chữ Việt Nam
Song Song 4.0.
6: Giấy Chứng
nhận Đăng ký Quyền Tác phẩm số
1850/2020/QTG do Bộ Văn hoá Thể thao
và Du lịch, Cục Bản Quyền cấp ngày 25/3/2020.
7: Công nghệ OCR (Optical Character
Recognition) – công nghệ
nhận dạng ký tự quang
học là ứng dụng công nghệ chuyên dùng để
đọc text ở file
ảnh.
8: Bệnh Alzheimer (AHLZ-high-merz) – là bệnh lý về não – tác động đến trí nhớ, suy nghĩ và hành
vi. Bệnh Alzheimer không phải là bệnh lão
khoa thông thường
hoặc bệnh thần kinh. Bệnh Alzheimer chiếm
khoảng 60-80% trong những bệnh làm suy giảm
trí nhớ. Hội chứng suy giảm trí nhớ là thuật ngữ tổng quát về việc mất trí nhớ và các khả năng tư duy đến mức nghiêm trọng có thể gây trở
ngại cho cuộc sống thường ngày.
9: Bệnh RSI (Repetitive
strain injury) là hội
chứng bệnh nghề nghiệp –
chấn thương
do căng lặp lại – thường gặp ở người
phải gõ bàn phím máy
vi tính, phải đẩy ‘chuột’
nhiều lần trong ngày.
10: Mật mã
Caesar là kỹ
thuật mã hóa đơn giản và phổ
biến nhất. Mật mã
Caesar thay thế
ký tự trên văn bản
thô bằng một ký tự
khác có vị
trí cách nó một khoảng
xác định tuỳ chọn trong bảng chữ cái. Ví dụ: với
độ dịch chuyển là 3, D sẽ trở thành A, E sẽ trở thành B, …, v.v.
Tên Caesar của
kỹ thuật mã hóa này
được đặt
theo tên của JULIUS CAESAR (vị
tướng La Mã đã sử dụng nó trong
các thư từ bí mật).
11: Mã Capcha (Completely
Automated Public Turing test to tell Computers and Humans Apart) là Phép thử tự động để phân biết máy tính với
con người. Mã
Captcha ra đời
nhằm hạn chế các phần
mềm tự động gây hại đến các trang web, trang dịch vụ. Mã
Captcha thường là các chữ,
số bị làm biến dạng hay sắp xếp lộn xộn để trở nên khó
đọc nhằm làm chậm thời gian truy cập. Mã Captcha được
thiết kế để xác nhận thao tác đúng bởi con
người (tỷ lệ 80%) hay robot (0.1%).
Mã
reCaptcha là những hình chụp, bản scan từ đời thật. Người sử dùng cần
nhận dạng và xác nhận
một số hình theo yêu
cầu của mã reCaptcha.
Mã
noCaptcha là
phiên bản cải tiến của mã reCaptcha. Mã noCaptcha chỉ yêu cầu đơn
giản là bạn cần kích chuột vào ô “không phải robot” nhằm giúp hệ thống
phân tích hành vi của bạn và nếu
có nghi ngờ
việc kích chuột diễn ra tự động
thì các mã Captcha hoặc mã reCaptcha sẽ hiện ra để yêu cầu thực
hiện thêm bước xác thực..
12: Chữ Braille – được LOUIS BRAILLE phát
minh (năm
1821) – là hệ thống chữ nổi giúp người mù, người khiếm thị sử dụng. Mỗi chữ Braille được
tạo thành từ 6 nốt nổi/chìm nhằm tạo ra một bộ
64 (26) kiểu tổ hợp nốt – mỗi kiểu thể hiện một ký tự có
thể giúp nhận dạng bằng cách sử dụng ngón tay rờ
mà ‘đọc’ được chữ.
13: Hợp đồng
thông minh Ethereum (HĐTM,
Smart Contract) được NICK
SZABO mô tả lần đầu tiên vào những
năm 1990. HĐTM là công cụ
để chính thức hóa và bảo mật
mạng máy tính khi giao
dịch bằng cách kết hợp các giao
thức với giao diện người dùng mà không cần
dựa trên sự tin cậy – hai bên trong
hợp đồng có thể đưa
ra các cam kết thông qua blockchain mà không cần
phải biết nhau hoặc tin tưởng lẫn nhau – song vẫn đảm bảo nếu các điều
kiện của hợp đồng không được thỏa mãn thì sẽ không
được thực
thi… Tuy nhiên! HĐTM thực chất không phải là một hợp đồng
pháp lý. HĐTM không cần bất cứ các bên trung
gian nào và giúp giảm
đáng kể chi phí hoạt động, chi phí hành chính.
HĐTM là Ứng dụng chạy trên blockchain và
được sử
dụng trong nhiều lĩnh vực khác nhau: các hệ thống tín dụng, xử lý thanh
toán, quản lý bản quyền
nội dung, v.v…. HĐTM giống như Hợp đồng
kỹ thuật số đươc
thực hiện bởi một bộ quy tắc cụ thể – các quy tắc này
được code của
máy tính xác định trước; và tất cả các node trong mạng có thể sao chép
và thực thi các quy
tắc đó. Giao
thức Bitcoin đã
hỗ trợ HĐTM trong nhiều năm qua và đặc biệt hữu ích trong
các việc chuyển/trao đổi tiền giữa hai/nhiều bên. Hệ thống HĐTM có thể tạo
ra các tài
sản được token
hóa, các hệ thống bầu chọn, ví tiền mã hóa, các sàn giao dịch phi tập trung, các trò chơi và ứng dụng di động;
mặt khác, cũng có thể
kết hợp HĐTM với các giải pháp blockchain khác như chăm sóc sức khỏe, từ thiện, chuỗi cung ứng, quản trị, tài chính phi tập trung (DeFi).
Tài liệu tham khảo
[1]. TRẦN TƯ BÌNH. Cách gõ
tắt chữ Việt không dấu. http://chuvietnhanh.sourceforge.net/CachGoTatChuVietKhongDau.htm
[2]. The Fourth Industrial Revolution.
[3]. KIỀU TRƯỜNG LÂM & TRẦN TƯ
BÌNH. Công
thức CHỮ VN SONG SONG 4.0 và Ví dụ. http://chuvietnhanh.sourceforge.net/CongThucChuVNSongSong4.0VaViDu.htm
[4]. KIỀU TRƯỜNG LÂM & TRẦN TƯ
BÌNH. Chữ VN Song Song 4.0.
http://chuvnsongsong.com/
[5]. KIỀU TRƯỜNG LÂM & TRẦN TƯ
BÌNH. Hướng
dẫn gõ nhanh chữ Việt trên máy vi tính bằng Kiểu
gõ CVNSS4.0 với Bộ gõ Evkey. http://chuvietnhanh.sourceforge.net/GoNhanhChuVietTrenMayViTinhBangKieuGoCVNSS4.0VoiBoGoEVKey.htm
Long Ngo
Nguồn: https://vietnamhoc.net/chu-vn-song-song-cvnss4-0-trong-boi-canh-cach-mang-cong-nghe-4-0/
-------------------
BÀI 8: CHỮ VN SONG SONG 4.0 VỀ MẶT
NGÔN NGỮ
(ngày 6-9-2022)
Ngôn ngữ là phương tiện
giao tiếp chính của con người, có thể tồn tại ở dạng lời nói, ký hiệu hoặc
chữ viết.
Ngôn ngữ gồm: ngôn + ngữ, trong đó: ngôn: lời lói, tiếng nói; còn ngữ là
biểu hiện dưới dạng mã hóa và
giải mã theo cách trực
quan nhằm lưu trữ thông tin và chuyển
giao tin nhắn dưới dạng chữ viết hoặc ký tự/ký hiệu. Như vậy, ngôn ngữ là dựa
trên quy ước xã hội.
Trong
phạm vi chủ đề này, tôi xin bàn
về hệ thống “chữ viết” của Cvnss4.0, nhằm làm sáng tỏ những
hoài nghi hoặc hiểu lầm trong các tranh luận
trước đây sau khi nhóm
tác giả công bố và
được cấp
bản quyền theo văn bản
pháp lý [850/2020/QTG] đã gây tranh
cãi lớn trên mạng xã hội từ
tháng 3/2020 đến
nay, vẫn còn “nóng”.
(i) Mặc dù,
nhóm tác giả đã chia sẻ quan điểm
không có ý định cải
tiến Chữ
Quốc Ngữ, mà
tôi rằng đây là “giải pháp hữu ích” trong việc gia tăng thêm
giá trị Chữ Quốc Ngữ trong bối cảnh Cách mạng công nghệ 4.0 hiện nay trên nhiều môi trường trong đó có
môi trường “số hóa”,
phục vụ cho “chuyển đổi số” hiện nay.
Ví dụ: tập tin HEX khi mã hóa
cụm từ “Chữ Quốc Ngữ” sẽ là
43681EEF2051751ED163206E671EEF, nhưng trong môi trường
máy tính biểu hiện ra sẽ là
“Ch‑ï Qu‑Ñc ng‑ï”. Nhưng Cvnss4.0 “Chữ
Quốc Ngữ” sẽ
là “Chuw Qocb wuw”, và
từ đây chuyển ra Chữ Quốc Ngữ sẽ dễ dàng hơn. Do Cvnss4.0 tuân thủ đúng theo quy định ASCII. Trong khi, bảng mã ASCII Tiếng Việt hiện cũng còn khá rối
rắm.
(ii)
Khi nói đến chữ viết chúng ta sẽ thấy có rất
nhiều chữ hiện nay đang tồn tại ở
Việt Nam như: khi
nói tiếng Pāli (पाळि)
(Phật giáo Nam Tông) - không có
chữ viết đi theo, nhưng
để biểu đạt có nhiều chữ viết trong đó chữ Chữ Khmer (không có thanh điệu),
bản thân chữ này lại
xuất phát từ chữ Pallava, chữ Brahmi. Nếu bạn muốn học tôi nghĩ
có khi cả
đời không hiểu hết, chưa kể hiện nay còn có Việt Khmer, Trung Khmer…
Trong
khi đó, Tiếng Việt sử dụng bảng chữ cái Latin có có hệ
thống thanh điệu phức tạp. Cho nên, nói Cvnss4.0 không có thanh điệu
là chưa phù hợp. Khi nói chữ viết
có thanh điệu hay không có thanh điệu
không phải biểu hiện về mặt tối ưu và tối giản
của chữ viết trong việc truyền tải thông tin.
(iii)
Tiếng Việt là một ngôn ngữ mẹ đẻ mà người ta thừa hưởng từ khi vừa được
sinh ra và
kéo dài liên
tục trong thời thơ ấu. Chính nhờ vậy mà dân tộc
ta không bị đồng hóa. Cả nước hiện nay chỉ mới có 27/54 dân tộc có
đầy đủ
tiếng nói và chữ viết
bản địa và chỉ có
dân tộc Hoa, Chăm, Khơ-me là có sẵn
tiếng nói và chữ viết
riêng của họ.
Chữ viết tiếng Việt
của chúng ta hiện nay là Chữ Quốc Ngữ, bộ chữ hiện dùng để ghi lại tiếng Việt dựa trên các bảng chữ cái của
nhóm ngôn ngữ Rôman với nền tảng là ký
tự Latinh.
Như
vậy, Cvnss4.0 dựa
trên nền tảng Chữ Quốc Ngữ nhằm phát triển song song trên nhiều
môi trường khác nhau (trong
đó có môi trường kỹ thuật số), nhằm tăng giá trị
biểu đạt, trực quan hóa, phát huy
bản sắc riêng về văn hóa tiếng
Việt thay vì chủ ta phải chủ động lệ thuộc quá nhiều vào tiếng Anh, tiếng Việt có dấu hiện nay.
Ví dụ: tên gọi
của mình theo tiếng Anh viết như thế nào cho
đúng, hay như giao dịch ngân hàng, bưu
điện, ... tất
cả điều không dấu, vậy có chuẩn
chung không? Hay như phiên âm tiếng nước ngoài...
(iv)
Hướng đến
sự tối giản hóa để đạt đến tính ưu việt, dễ dàng, linh hoạt nhằm đơn giản hóa ý nghĩ và giao
tiếp: Toki-Pona, Esperanto, Interlingua, Quenya, Volapük… Như vậy, khi một ngôn ngữ nào phát
sinh, không suy nghĩ trước
trong não bộ của con người, không nhất thiết phải tuân thủ của “ngôn ngữ tự nhiên" mà Cvnss4.0 tuân thủ theo “ngôn ngữ xây dựng” và ngôn ngữ
hình thức hay ngôn ngữ thông tin, nó khác
với ngôn ngữ giao tiếp thường nhật.
Ví dụ: Interlingua hay tiếng
Khoa học Quốc tế
(mã ngôn ngữ ISO 639 ia, ina) là một
ngôn ngữ phụ trợ quốc tế (IAL), được Hiệp hội Ngôn ngữ Phụ trợ Quốc tế
(IALA) phát triển từ năm 1937 và 1951. Đây là ngôn ngữ
phụ trợ quốc tế được sử dụng rộng rãi thứ hai
hoặc thứ ba, sau Esperanto và sau là
Ido, và là ngôn ngữ phụ trợ tự nhiên được sử dụng rộng rãi nhất, nói cách khác,
từ vựng, ngữ pháp của nó và
các đặc điểm khác là phần lớn
bắt nguồn từ ngôn ngữ
tự nhiên. Ban đầu, cũng có rất nhiều
tranh cãi về nó. Do vậy, Cvnss4.0 cũng giống như “Lingua
franca” (còn gọi là ngôn ngữ
cầu nối/hỗ trợ/đi làm/du lịch) là “dạng ngôn ngữ phái sinh”, một cách hệ thống,
dùng để giao tiếp.
Tóm
lại, hiện tượng khúc xạ trong ngôn ngữ, giao thoa, cải
biên... là điều bình thường trong tiến trình của một ngôn ngữ. Để giữ được bản sắc riêng của mình, tôi lấy ví
dụ ngôn ngữ của Nhật Bản rất phức tạp, những họ vẫn tôn trọng
tôn trọng sự sáng tạo
cá nhân và
giữ gìn nó để trở thành một cường quốc.
Gìn giữ được sự trong sáng của tiếng Việt là giữ gìn được
nền tảng văn hóa ngôn
ngữ Việt Nam mà
Cvnss4.0 đã đạt
được thống
nhất trong quy ước, có quy luật
và nguyên tắc sử dụng riêng. Nhìn sang các nước
khác trong khu vực, như Nhật Bản từng chịu ảnh hưởng sâu đậm của Hán văn, nhưng họ vẫn giữ được bản sắc văn hóa của riêng
mình, ngôn ngữ của họ rất phức tạp có đến 3 bộ vần đó là: higarana
và katakana biểu âm; bộ kanji dựa trên chữ Hán biểu ý. Ngoài ra, còn
có tiếng Nhật
Romaji là cách để tiếng
Nhật được lan
tỏa rộng trong cộng đồng và ra thế giới.
Long
Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/829485318465584/
-------------------
BÀI 9: CVNSS4.0 - THUỘC NHÓM CÁC NGÔN NGỮ IAL?
(ngày 8-9-2022)
Chữ VN Song
Song 4.0 (Cvnss4.0) dưới
góc độ tìm hiểu của tôi được
xem là ngôn
ngữ được
xây dựng (constructed
languages) thuộc nhóm
các ngôn ngữ "auxiliary" nghĩa
là bổ trợ song song cho một mục
đích nào đó về văn hóa, thiết
kế và nghệ thuật… mà thế giới
phân loại, tồn tại hiện nay khoảng 40 ngôn ngữ như thế. Các ngôn ngữ bổ trợ quốc tế (IAL -
International auxiliary language) là các ngôn ngữ
được xây dựng để cung cấp giao tiếp dễ dàng, nhanh chóng hơn
hoặc được
cải thiện giữa các đối tượng giao tiếp hoặc một phần đáng kể, mà không
nhất thiết phải thay thế ngôn ngữ mẹ đẻ mình [Otto Jespersen,
1908]
Trong 11 ngôn ngữ
sau đây tôi thử làm
phép phân tích để thấy được giá trị lợi
ích mà Cvnss4.0 mang lại.
1) Esperanto (L. L. Zamenhof, 1887) là
một bác sĩ nhãn khoa tạo ra;
2) Volapük (Johann Martin
Schleyer, 1879) là mục
sư tạo ra;
3) Ido (Louis Couturat, 1907) khởi xướng là tiền thân
của chữ Novial sau này;
4) Interlingua (IALA, 1951) một
tổ chức có tên là
Hiệp hội Ngôn ngữ Phụ trợ Quốc tế Hoa Kỳ tạo ra;
5) Kotava, (Staren Fetcey, 1978)
6) Interlingue (Edgar de Wahl,
1922)
7) Lingua Franca Nova (C. George Boeree, 1965)
8) Novial (Otto Jespersen,
1928)
9) Lojban (LLG, 1987), sau này là Loglan
10) Toki Pona (Sonja Lang, 2001)
11) Klingon (Marc Okrand, James
Doohan, Jon Povill, 1985)
Có những
ngôn ngữ như Esperanto (Quốc tế
ngữ) có số lượng người dùng rất cao gần
200,000 người dùng.
Có thể thấy như: các ngôn ngữ
này điều được sáng tạo ra từ
bằng việc cải tiến bảng chữ cái Latinh, nhằm
để đơn
giản hóa suy nghĩ và
giao tiếp (Toki
Pona); giao tiếp giữa những người thuộc các nền tảng
ngôn ngữ khác nhau, như
một phương tiện dịch máy tiềm năng và như
một công cụ để khám phá sự
giao thoa giữa ngôn ngữ của con người và phần mềm (Lojban,
1987); hay như các từ vựng được tạo ra ngôn ngữ
Đức và Roman, ngữ
pháp của nó bị ảnh
hưởng bởi tiếng Anh (Novial, 1928). Hoặc chỉ để tạo hệ thống ngữ pháp cực kỳ đơn giản và dễ học
(Lingua Franca Nova, 1965) …
Cvnnss4.0 có tính
kế thừa như: Toki Pona, Lojban, Nova nếu
xét trên các đặc tính trên.
Theo lý thuyết
ngôn ngữ Sapir-Whorf,
điều này có tầm quan
trọng lớn hơn nhiều, có một vai
trò quan trọng hơn nhiều khi tổ chức, suy nghĩ hoặc
thậm chí nhận thức thế giới. Do vậy, để kiểm tra ảnh hưởng của ngôn ngữ đối với suy nghĩ
của người nói, lý thuyết
này chỉ ra rằng vai
trò của (hoàn cảnh địa lý, bối cảnh văn hóa) khi
đưa ra một khuôn khổ để xây dựng nhận thức của chúng ta và để chúng ta có khả
năng quan sát về thế
giới trong phạm vi được
áp đặt bởi xã hội.
Điều này, giúp ta khẳng định bạn không thể giải thích sự vật, hiện tượng bằng các ngôn ngữ khác bởi mỗi ngôn ngữ có các
thuật ngữ và khái niệm
riêng của nó.
Ví dụ:
khi nói về
con nước của
người miền
Tây (nước rong, nước ròng, nước lớn, nước kém, …). Hay như, thuật ngữ “umami” trong khái niệm tiếng Nhật đề
cập đến một hương vị bắt nguồn từ nồng độ
glutamate và đối
với các ngôn ngữ khác không có
bản dịch cụ thể, rất khó để
mô tả.
Ở khía cạnh
nào, Cvnss4.0 có mô-tip khá giống
với Loglan
(http://www.loglan.org/?fbclid=IwAR2SWDNg3cBEk2uBlxkDDvHRvOpT2c4J7OdnsozfR4oWVDgW5yPqst-pZfE)
Tóm lại, việc xuất hiện thêm Cvnss4.0 cũng phù hợp
với tiến trình chung của
các ngôn ngữ được xây dựng trên thế giới. Vấn đề bây giờ làm sao
để khai thác hiệu quả mà các
tính năng Cvnss4.0 mang lại.
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/830803431667106/
-------------------
BÀI 10: CHỮ QUỐC NGỮ
TRONG TIẾN TRÌNH LỊCH SỬ DÂN TỘC
(ngày 15-9-2022)
Chữ Latinh là loại văn tự chữ cái được sử dụng rộng rãi nhất trên thế giới hiện nay. Chữ
Quốc Ngữ là
tập hợp các chữ cái
Latinh và dấu phụ được dùng cùng với các chữ cái
đó để viết tiếng
Việt. Như vậy, thông qua việc thêm dấu phụ lên các
chữ cái có sẵn, ghép
nhiều chữ cái lại với
nhau, sáng tạo ra chữ
cái mới hoàn toàn hoặc
gán một chức năng đặc biệt do một bộ đôi hoặc bộ ba chữ
cái. Vị trí của các
chữ cái mới này trong
bảng chữ cái có thể
khác nhau, tùy thuộc từng ngôn ngữ.
Bảng chữ cái Latinh
đầu tiên chỉ có 21 chữ cái thiếu
đi /J/, /G/, /Y/, /Z/, /W/. Do sự phát triển
của từng ngôn ngữ của từng quốc gia mà có sự
bổ sung biển đổi cho phù hợp như:
trong tiếng Đức
người ta thêm dấu umlau trong các chữ
cái ⟨ä⟩, ⟨ö⟩, ⟨ü⟩ của
tiếng Đức.
Chữ Quốc
Ngữ giai
đoạn mới hình thành, trên
chặng đường
lịch sử hàng trăm năm chỉnh lý, bổ sung và phát triển
nhưng chưa đủ phổ biến để coi là văn
tự chính thức mãi cho đến 1880, các văn kiện
chính thức được dùng Chữ Quốc Ngữ, có lẽ cụ
Trương Vĩnh Ký
đã có công trong việc
truyền tải chữ này qua nhiều tác phẩm mà ngày
nay chúng ta mới có dịp thưởng
lãm, ví như:
Truyện thơ Lục Vân Tiên.
畧畑䀡傳西銘
(Trước đèn xem chuyện
Tây Minh)
Đến những năm thời kỳ đầu 1900s, thì cả nước bắt đầu cùng học Chữ Quốc Ngữ Latinh. Như vậy, để thể hiện tiếng Việt,
người ta dùng phương pháp ký âm tiếng
Việt bằng chữ
cái Latinh, đó là việc
chuyển thể việc nói tiếng Việt trở thành các ký
tự Latinh thông qua việc thêm dấu phụ trên giấy.
Nói về việc
cải tiến Chữ Quốc Ngữ có thi sĩ
Tản Đà (1919), nhà báo Nguyễn Văn Vĩnh (1929), nhà giáo Dương Tự
Nguyên (1929), sử gia
Trần Trọng Kim
(1929) … các tác giả viết nhiều bài tranh luận trên Trung Bắc tân văn xoay quanh
vấn đề lý do sửa đổi Chữ Quốc
Ngữ bỏ dấu phụ. Đặc biệt, Vi Huyền Đắc (1929)
đề xuất chữ viết ghi âm nhưng
mượn chữ
Hán, Nhật để chế
ra con chữ thay chữ Latin. Sau 1945,
Ban chuyên môn Bình dân học vụ
Trung ương (1946) đã
soạn thảo văn bản cải cách Chữ Quốc Ngữ. Việc cải tiến trong bối cảnh hội nhập quốc tế từ những năm 2000s khi xuất hiện các ký hiệu,
từ ngữ mới do Internet phổ biến cũng dần chấp nhận nhưng những cuộc tranh luận nảy lửa phải kể đến Bùi Hiền
(2017), Hồ Ngọc Đại
(2018), …
Ngày nay, nếu dùng thao tác này
cho máy tính
sẽ khó khăn gấp nhiều lần, thay vì thể
hiện:
Trước đèn xem chuyện
Tây Minh -> Trusx denl xem chylf
Tayy Mihp (Cvnss4.0)
Công việc này nó sẽ
giảm dung lượng
xử lý của máy tính
bằng việc mã hóa. Bạn
thử tưởng tượng nếu bạn ghi nhớ
chữ tiếng Việt
có dấu tốn 10bytes, bạn dùng Chữ VN Song Song 4.0 (Cvnss4.0) sẽ tiết kiệm hơn rất nhiều. Giả định xử lý lên đến
1GB thì bạn sẽ tiết kiệm rất nhiều dung lượng.
Chữ Nôm thông qua qua một trường
hợp khác cho thấy không chịu ảnh hưởng bởi Chữ Quốc Ngữ! Với lịch sử định cư trải qua hơn 500 năm, hầu hết cư dân người Kinh ở
khu vực Tam Đảo (Vạn Vĩ, Vu Đầu và Sơn Tâm) cũng như một vài nơi khác
ở Quảng Tây (chủ yếu tập trung tại Đông Hưng) thuộc Trung Quốc
ngày nay đều có chung nguồn
gốc là người Đồ
Sơn (Hải Phòng, Việt Nam), còn lại số
ít người Kinh trong đó có
nguồn gốc từ một vài địa phương ven biển của Việt
Nam di cư đến.
Người Kinh Tam Đảo
vốn nói tiếng Việt và sử dụng phổ biến chữ Nôm, có lối giao
tiếp như người Việt chỉ
có điều họ không dùng Chữ Quốc Ngữ. Dân số người Kinh
Tam Đảo hiện
nay tương đương
với vùng ĐBSCL của chúng ta. Như vậy, xét lại lịch sử cho thấy
Chữ Nôm bắt đầu hình thành và
phát triển từ thế kỷ X đến thế kỷ XX thì hạn chế.
Chữ này tồn tại 10 thế kỷ, nếu xét về
thời gian Chữ Quốc Ngữ còn thua xa
nhưng do tính ứng dụng phổ biến nên được ưa chuộng và sử dụng
rộng rãi cho đến ngày nay.
Qua đó cho
thấy, Chữ Quốc
Ngữ, chữ Latinh và chữ
Nôm cùng chữ Hán xét về gốc là hai hệ
chữ dùng để viết tiếng Việt, chúng
có vai trò
khác nhau nhưng bổ trợ cho nhau
trong chiều dài lịch sử và văn
hóa Việt Nam mà còn phụ thuộc
vào hoàn cảnh địa lý của buổi
ban đầu. Việc
nghiên cứu chữ viết hay ngôn ngữ rất vất vả, gian nan thậm chí tiêu tốn nhiều thời gian, chưa kể kinh phí
cho nó rất
tốn kèm không phải ai cũng đồng cảm được. Dù đứng dưới vai trò nào cá
nhân, nhóm hay tổ chức nếu đứng ở
góc độ nào đó, việc
đề xuất có ích nhằm
giải quyết bài toán nào
đó điều rất được trân trọng. Tuy nhiên, vai trò
của tổ chức bao giờ cũng chiếm ưu thế hơn.
Hiện nay, mặc dù Chữ
Quốc Ngữ được
dùng phổ biến nhưng vẫn có nhóm
nghiên cứu chuyên sâu Hán Nôm! Ví dụ:
Ủy ban Phục sinh
Hán Nôm Việt Nam đã
cho chuẩn hóa 5.524 ký tự
chuẩn, chiếm khoảng 98% lượng
sử dụng hàng ngày của
tiếng Việt hiện
đại. Qua đó
cho thấy, tùy vào nhu
cầu và mục đích khác nhau mà
có thể thêm/bớt hoặc bổ sung để cho các tiện ích trong đời
sống được
tối ưu hóa trong lúc
thao tác hóa chữ viết
trên các công cụ.
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/835634777850638/
-------------------
BÀI 11: CHỮ VN SONG SONG 4.0 TRONG HÀNH TRÌNH TÌM TIẾNG NÓI ĐỒNG
THUẬN
(ngày 1-10-2022)
Có hơn
7.000 ngôn ngữ trên thế giới này [1]. Con số đó không ngừng tăng lên hàng
này, bởi vì chúng ta đang
học thêm về các ngôn
ngữ trên thế giới mỗi ngày. Và hơn thế
nữa, bản thân các ngôn
ngữ cũng đang thay đổi hàng ngày. Chúng ta đang sống trong một thế năng động, được
nói bởi những cộng đồng có cuộc sống được định
hình bởi thế văn hóa lịch sử tồn tại trong một thế giới đang thay đổi nhanh chóng. Đây
là thời kỳ mọi thứ diễn ra quá nhanh.
Khoảng 40% ngôn ngữ hiện nay đang bị đe dọa, thường chỉ khoảng 1.000 người
nói và sử
dụng. Trong khi đó, chỉ có 25 ngôn ngữ
thường xuyên được sử dụng và chiếm
hơn 4 tỷ người trên Trái đất này. Việt Nam đứng
thứ 20 nhưng tôi đánh giá
rằng, không chính xác mà
là 15 trên thế giới về mức độ sử dụng. Bởi dân số của
chúng và cộng động hải ngoại đã vượt quá 100 triệu dân.
Trong đó chữ
tiếng Việt có lợi thế bởi có gốc
từ hệ Latinh nên Chữ
Quốc Ngữ có sự kế thừa và phát
triển rất nhanh (tiếng Anh, tiếng Pháp, tiếng Tây
Ban Nha… Mặc khác, gốc nghĩa 80% từ vựng tiếng Việt
lại có thành tố Hán Việt.
Hay nói khác đi, Tiếng Việt là chủ thể
tạo nên nhiều ngôn ngữ khác từ sự kế thừa.
Tuy nhiên, chỉ
khoản 3.800 ngôn ngữ là "sử dụng hệ thống chữ viết đã được thiết lập". Điều này bao gồm việc viết các hệ thống cho các ngôn
ngữ đã tuyệt chủng và các ngôn
ngữ xây dựng, hệ thống viết tắt, chữ nổi Braille và các hệ thống
ký hiệu khác, và nhiều
hệ thống chữ viết được liệt kê hiếm khi
được sử
dụng. Việc thiết lập hệ thống chữ viết cho nhiều môi trường khác nhau là
rất cần thiết vì nó sẽ đa
dạng hóa việc truyền tải “ý thức số/consciousness”. Đây
là một phương thức quan trọng để truyền tải cho brain-computer. Giống như một đứa bé sinh ra,
việc học ngôn ngữ nào là do môi
trường và xã hội của
nơi đó quyết định, đứa bé sẽ không tự quyết định được
việc học ngôn ngữ nào. Tương lai, các con robot máy tính cũng
vậy, chúng sẽ tự học và tự
nhận thức và tự giao
tiếp bằng ngôn ngữ của chúng do chúng ta tạo ra [3].
Chữ Việt Trí
(2012), là một bảng chữ cái thay thế
cho tiếng Việt
do Tôn Thất Chương phát kiến ra. Ông khuyến
khích sử dụng Chữ Việt
Trí để viết
thư pháp, tiểu thuyết và nhật ký,
để giao tiếp bí mật,
hoặc chơi các trò chơi,
viết thư thông minh và
cho các chức
năng văn học và tôn
giáo. Đặc điểm đáng chú ý: Đây loại hệ thống chữ viết: dựa vào bảng chữ cái Latinh;
Hướng viết:
từ trái sang phải theo hàng ngang. Chữ
Việt Trí bao gồm: 29 chữ
cái, 6 âm và 10 chữ số. Dùng để viết cho: Tiếng Việt.
Chữ Vòng,
nghĩa đen là "chữ viết vòng tròn", là một bảng chữ cái thay
thế cho tiếng Việt do Albert Nguyễn sáng chế (2014). Động lực tạo ra Chữ
Vòng xuất phát từ mong muốn bắt chước khả năng của người Hàn Quốc và Nhật Bản, những quốc gia đã từng
sử dụng tiếng Trung Quốc làm hệ thống chữ viết duy nhất, để duy trì việc sử dụng các ký tự
Trung Quốc cùng với
hệ thống chữ viết phiên âm của
riêng họ.
Đề xuất cải tiến bảng chữ cái và
chính tả tiếng Việt (Bùi Hiền,
2016) gây bão mạng.
Nhóm tác
giả CVNSS 4.0, công bố công trình
nghiên cứu "Chữ Việt Nam song song
4.0" (2020). Nếu các
công trình trước đây là quá rắc
rối trong các quy tắc,
luật định.
Chưa kể là khó thể
hiện trong môi trường máy tính. Chúng
ta phải nhìn nhận rằng để cho một chữ viết tốt hơn trong môi trường nào đó nhất
là chữ tiếng Việt (có dấu), có hai nguyên tắc
trong quá trình nghiên cứu: (i) khi nghiên
cứu phải có phương pháp dựa trên kế thừa
trước đó; tức là trước
khi làm phải
quy trình, phương pháp, các bước kiểm soát, đối tượng thực hiện, các điều kiện kèm theo, các kỹ
thuật sẽ sử dụng… trong quá trình
nghiên cứu luôn có sự
điều chỉnh
để chữ viết trở nên tối ưu
hơn; (ii) Phải làm thử nhiều
lần và chấp nhận phản ứng dư luận; nếu sai quay lại (1) điều chỉnh để tiếp tục làm tiếp. Tôi nhận thấy, nhóm tác giả đã
không dừng lại mà luôn
sẵn sàng chia sẻ cái của
mình làm, cái mình mong muốn
ra cộng đồng, chấp nhận cho mọi người phán xét miễn
phí. Liệu như vậy, có quá
bất công với nhóm tác giả CVNSS 4.0 hay không (?)
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/847555806658535/
-------------------
BÀI 12: TIỆN ÍCH NHỎ
TỪ CHỮ VN SONG SONG 4.0 MANG LẠI
(ngày 19-10-2022)
Đối với chúng ta tài nguyên số
hay nói khác đi dữ liệu trên máy vi tính là
cực kỳ quan trọng, thậm chí nó quý hơn
vàng. Không có dữ liệu
thì đừng bao giờ nói chuyện
a,b,c thuật
toán hay AI gì đó. Bởi trong thời đại công nghệ 4.0 như hiện nay, việc soạn thảo và lưu trữ
các file trên máy vi tính (PC hay Laptop) đã trở nên phổ biến,
bởi dữ liệu tạo ra theo thời
gian rất ý nghĩa với chúng ta. Tuy nhiên, việc đặt tên và tổ
chức file, folder (thư
mục) như thế nào cho
hợp lý, hiệu quả và hạn chế
những rủi ro thì không
phải ai cũng thực hiện đúng, ngăn ngừa một số lỗi ngớ ngẩn thì không phải
ai cũng biết. Đa phần người dùng Việt
Nam thường mắc
phải một số lỗi khi đặt tên file, folder như: đặt tên bằng tiếng Việt
có dấu, đặt tên quá dài, tạo
quá nhiều folder lồng vào nhau….
Việc đặt tên như vậy sẽ thuận lợi cho người
sử dụng tiếng Việt, tuy nhiên sẽ gây khó khăn,
hạn chế, thậm chí gây ra lỗi
trong tìm kiếm, copy, di dời
file và nhất là khi phục
hồi (recovery) file bị
xóa, lâu dần sẽ bị trùng lắp dữ liệu phái sinh, trong khi
dữ liệu nội sinh không cần thiết… do đa phần các phần mềm, hệ điều hành (OS) đều do các công ty nước
ngoài phát triển trên các nền tảng
ngôn ngữ lập trình nhất định (ngôn ngữ lập trình là ngôn ngữ
không có dấu), chủ yếu bằng tiếng Anh (English) và không hỗ trợ tốt hoàn toàn tiếng
Việt. Quá trình thao tác hóa,
bộ nhớ cache quá nhiều nhất là dữ
liệu phi cấu trúc tạo ra dẫn đến
bộ nhớ chứa rác nhiều hơn chứa những thứ cần thiết từ dữ liệu mang lại.
Ngoài ra,
font tiếng Việt thường
không được tích hợp sẵn trong các hệ điều
hành cũng như các chương
trình mà phải cài đặt thêm các Fonts tiếng Việt vào mới sử
dụng được
(Một số lỗi điển hình mà chúng
ta có thể nhìn thấy như: Khi ta gửi kèm file (attach file) đặt
tên bằng tiếng Việt có dấu qua một số hệ thống mail hay một số chương trình, khi download về, file sẽ bị lỗi tên và đổi
thành tên khác không có
dấu…). Các phần
mềm crack, các bản chưa cập nhật hoặc các chương trình cũ có vô
số lỗi sẽ làm chậm
máy thậm chí bị đơ,
việc tạo ra các file có
dẫu tiếng Việt
sẽ ngốn thêm tài nguyên
của máy tính, nhiều máy sẽ bị
liệt…
Vì vậy
để thực hiện đặt tên file, folder thật sự hợp lý, hiệu quả và hạn
chế phát sinh lỗi, nên chú ý một
số nguyên tắc sau:
- Nên đặt
tên bằng chữ không dấu, có thể sử dụng dấu “-” hay “_” thay thế các khoảng trống. (vd:
thay vì đặt
tên “báo cáo.doc” nên đặt là “bao cao.doc” hay “bao_cao.doc”). Vậy
nếu Chữ VN Song
Song 4.0 (Cvnss4.0) bạn
đặt là baoj caoj.doc
- Đặt tên ngắn gọn, dễ hiểu, có ý nghĩa; hạn chế tối thiểu việc đặt tên quá dài (vd:
thay vì đặt
tên “Thong tu lien tich so 01 ve thi
hanh an dan su.doc” nên đặt là “TTLT01
THADS”), nếu đặt thogy tuo.doc thì
sao?
- Đối với các file cần sắp xếp theo thời gian, địa điểm,
có thể thêm địa điểm, ngày, giờ vào tên
file để dễ
dàng sắp xếp, tìm kiếm (vd: thay vì “picture1.png” nên đặt là “DaLat_11.07.2020_picture1.png”). Còn
đặt Dal Latr.png
- Nên lưu
ý thứ tự sắp xếp tên trong hệ
điều hành (vd: trong window sẽ sắp xếp ưu tiên theo thứ
tự: “ký tự đặt biệt” => “số”
=> “ký tự thường”; nghĩa là các
file được sắp
xếp theo thứ tự “@.doc” =>
“1.doc” => “a.doc”).
- Không nên
tạo quá nhiều lớp folder lồng vào nhau (vd:
D:\FolderA\FolderB\FolderC\FolderD\FolderE\
- Còn các
Folder/file đặt theo
Cvnss4.0 thì rất tuyệt, bởi dữ liệu của bạn chỉ có bạn
biết nếu như người đó không biết
gì về Cvnss4.0.
Trên đây
là tiện ích nhỏ mà
Cvnss4.0 mang lại, nó thể tính
riêng tư rất cao, hạn chế rủi ro và
lộ thông tin không cần thiết. Nếu có thêm vài
cái pass từ Cvnss4.0 lên Floder nữa
thì đúng là chỉ có
bạn hiểu những gì mình lưu trữ
và quản lý các dữ
liệu trong máy tính của
bạn mà thôi.
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/861572345256881/
-------------------
BÀI 13: CHỮ VN SONG SONG 4.0 DƯỚI GÓC NHÌN MÃ HÓA
(ngày 6-1-2023)
Người đã sáng chế
ra cách mã
hóa Caesar thú vị là vị
hoàng đế Julius
Caesar. Kỹ thuật
này đã được phát triển vào khoảng năm 100 Trước Công nguyên.
Hoàng đế Caesar đã
dùng nó để
gửi những mệnh lệnh quan trọng cho những tướng sĩ trên chiến trường. Do đó, nếu bọn giặc có bắt
được người
truyền tin thì cũng không thể đọc và hiểu được
nội dung của bức thư mã hóa đó.
Kiến thức này thật sự rất hữu ích và được
áp dụng cho tới ngày
hôm nay. Nhiều người cho rằng, CVNSS4.0 giống chữ mã hóa
hơn. Tôi nghĩ còn hơn
thế nhưng hãy từ từ
khám phá.
1. Nên hiểu rõ ba
thuật ngữ:
Hashing, Encryption, Encoding
Hash là một
chuỗi được
tạo ra thông qua một thuật toán, để bảo vệ tính toàn
vẹn của dữ liệu. Điều đặc biệt là không
thể lấy được giá trị đầu vào sau khi
chuyển đổi.
VD: user -> pass -> server [salted password ->
hash] = database. Nếu khớp
lệnh user mới truy cập được.
Encryption là quá
trình chuyển đổi dữ liệu thành một định dạng không thể đọc được để
giữ an toàn và bảo mật
cho chúng, chỉ những người được
ủy quyền mới có thể
đảo ngược
nó.
VD: Blockchain sẽ có “Public key” và “Private key”. Khi dữ liệu được gửi qua HTTPS, nó sẽ được mã hóa bằng
public key, khóa này được lưu trữ trong trình duyệt. Private key chỉ bên nhận
dữ liệu sở hữu và phải được
giữ bí mật. Quá trình này là
SSL handshake – xác thực
server khi connecting với
client, symmetric encryption sẽ đảm nhận việc mã hóa
dữ liệu.
Encoding là một
quá trình thay đổi dữ liệu sang một định dạng mới thông qua một lược đồ có sẵn, công
khai. Không yêu cầu khóa
chỉ cần “bạn học nó, biết, hiểu” là đã mã hóa
rồi tự mình giải mã nó. Để
đảm bảo dữ liệu được toàn vẹn và có
thể được
sử dụng bởi nhiều hệ thống thì chỉ cần
tối thiểu 2 người hoặc một nhóm người hiểu biết về nó. Nguyên lý này
cũng dựa trên một ví dụ đơn
giản thường
thấy trong công nghệ thông tin như các thuật toán cho encoding: Base64, ngoài ra có
ASCII, Unicode, URL Encoding…
Ví dụ:
Mật mã Caesar là một dạng
mật mã thay thế, trong đó mỗi
ký tự ở văn bản ban đầu sẽ được thay thế bằng một ký tự
khác, có vị trí cách
nó một khoảng xác định trong bảng chữ cái. Nếu chúng ta chuyển mỗi chữ cái theo ba
vị trí sang bên phải, thì mỗi chữ
cái trong văn bản rõ gốc của
chúng ta sẽ được thay thế bằng một chữ cái sau nó
ba vị trí bên phải.
Chẳng hạn, với văn bản “HELLO WORLD” bằng cách sử dụng dịch chuyển sang phải là 3, chữ H sẽ được thay thế bằng K, E sẽ được thay thế bằng H, ... Và thông điệp được mã hóa cuối cùng cho HELLO WORLD sẽ là KHOOR ZRUOG. Bạn có thể
thấy thông điệp này nhìn như: vô nghĩa, phải không? Đây là chính
ý nghĩa của việc mã hóa,
biến một văn bản rõ đọc được bằng mắt thường thành một văn bản vô nghĩa trong
mắt con người
nhưng đằng sau đó tưởng
chừng vô nghĩa lại có ý nghĩa quan trọng tùy theo mục
đích sử dụng là gì.
2. Hiểu
CVNSS4.0 đơn giản
như Encoding
CVNSS4.0 là hiểu
một cách đơn giản thì nó là
Encoding có thể hình dung như bạn học Mật mã Caesar. Việc này rất quan trọng vì mã hoá có
vai trò quan
trọng trong giao dịch điện tử để đảm bảo độ bảo mật, toàn vẹn của thông tin khi truyền trên mạng. Hãy thử tưởng
tượng các bạn muốn kể một câu chuyện bí mật cho
người bạn thân của mình. Để bảo mật câu chuyện riêng tư không
bị lộ ra ngoài bạn
sẽ cần dùng đến CVNSS4.0
Cũng giống như các loại mật mã thay
thế khác, CVNSS4.0 có vẻ giống
ý tưởng mật
mã Caesar bạn có nghĩ vậy
không? Bạn hãy có tôi
biết ý kiến của mình! Càng tìm hiểu
sâu về CVNSS4.0 bạn sẽ tìm thấy nhiều điều thú vị không
chỉ là con chữ và ngôn
ngữ đâu nhé!
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/919081789505936/
-------------------
BÀI 14: NHỮNG CHỮ CÁI
DÙNG "LẬU"
(ngày 7-1-2023)
4 chữ F, J, W và Z không có
trong bảng cái tiếng Việt lại được sử dụng thường xuyên và ngày càng
phổ biến.
******
1. Nhóm
ký tự f, j, w, z và cách viết
tắt
Sinh thời, Cụ Hồ là người rất quan tâm đến việc sử dụng và bảo
vệ tiếng Việt.
Người thường
nhắc nhở mọi người phải biết giữ gìn và
quý trọng tiếng Việt. Ngôn ngữ do Người sử dụng giờ ta so sánh đối chiếu lại sẽ thấy rất uyển chuyển, linh hoạt, đảm bảo sự trong sáng của ngôn từ, có tính chính
xác cao, sức truyền tải lớn, phù hợp với
từng đối tượng hướng
tới. Người
cũng từng nói việc dùng chữ viết là theo
cách riêng của mình nhưng điều này không làm
thay đổi chữ cái tiếng
Việt.
Ví dụ:
Cuốn “Đường
Kách mệnh” (1927) bảo vật quốc gia, chữ K thay chữ C.
Hay như, Bản
Di Chúc của Hồ Chí Minh là mô hình của
chính tả viết theo ý mình thích, được
Người soạn
thảo, viết từ năm 1965 đến năm 1969. Chưa vội bàn đến nội dung di chúc, về hình thức
trong văn viết mà Người
thường sử dụng là "d" thay "đ", "f" thay
"ph", "k" thay
"c", "z" thay "d",”gi”, “ng” thay
“ngh, nhưng có ai nói Người
viết sai chính tả hay viết tắt cực đoan chứ (?). Nếu nghiên cứu sâu sẽ thấy
cách viết của Người.
(i) không
viết dấu sắc ở các từ tận cùng bằng c, ch, p, t (tắc âm),
(ii) Không viết
đủ chữ, mà viết tắt
rất nhiều bằng việc tinh gọn con chữ.
2. Bảng chữ cái hiện
nay và bất cập
Bảng chữ cái Latinh
là hệ thống chữ viết dùng bảng chữ cái tiếng Anh gồm 26 ký tự được sắp xếp theo thứ từ A đến Z được sử dụng rộng rãi nhất hiện nay trên thế giới.
Bảng chữ cái Latinh
= Bảng chữ cái tiếng Việt + (F,
J, W, Z) – (Ă, Â, Đ, Ê, Ơ, Ô, Ư)
Chữ Quốc
Ngữ là một loại chữ viết tiếng Việt, được
ghi bằng tập hợp các chữ cái
Latinh (nhưng loại bỏ nhóm ký tự:
F, J, W, Z) và dấu phụ được dùng cùng với
các chữ cái đó.
Bảng chữ cái tiếng
Việt = Bảng chữ
cái Latinh – (F, J, W, Z) +
(Ă, Â, Đ, Ê, Ơ, Ô, Ư) + thanh điệu
Chữ VN Song
Song 4.0 được
ghi bằng tập hợp các chữ cái
Latinh (thêm vào nhóm ký
tự F, J, W, Z) và loại dấu phụ được dùng cùng với
các chữ cái đó.
Bảng chữ cái VN Song Song 4.0 = Bảng chữ cái Latinh
– (Ă, Â, Đ, Ê, Ơ, Ô, Ư) - thanh điệu
Như vậy, chữ viết của Việt Nam hiện
nay được sáng
tạo trên việc sử dụng ký tự
Latinh để ghi âm tiếng
Việt nhưng đã
phức tạp hóa bằng “các chữ kép”
thay thế cho “nhóm ký tự F, J, W, Z” khiến cho tiếng Việt khó hòa nhập quốc tế. Vô tình chúng
ta sử dụng nhóm ký tự F, J, W, Z hiện
nay là đang dùng lậu vì theo quy
định pháp lý nhóm ký tự F, J, W, Z nằm ngoài bảng chữ cái tiếng Việt.
Dĩ nhiên, nhưng ai đang sử dụng máy tính thì các
ký tự trên F, J, W, Z đã
trở nên quen thuộc, chủ yếu phục vụ việc gõ các
ký tự riêng của tiếng Việt là ă,
â, đ, ê, ơ, ư. Vì vậy,
việc thừa nhận nhóm ký tự F, J, W, Z trên trong bảng
chữ cái tiếng Việt là điều cần thiết để thống nhất sử dụng về chuẩn chính tả tiếng Việt trên môi trường máy tính và
nếu tăng lên 33 ký tự
trong sách giáo khoa thì bảng
chữ cái tiếng Việt hiện
nay có tổng cộng 29 chữ cái được sắp xếp theo thứ tự như sau: a, ă, â, b, c, d, đ, e, ê, g, h, i, k l, m, n, o, ô, ơ, p, q, r, s, t, u, ư, v, x,
y sẽ thêm nhóm ký tự f, j, w, z.
3. Vì sao phải bổ sung nhóm ký tự f, j, w, z
Trong luật hiện nay cũng nếu khá rõ
“chủ doanh nghiệp cần đặc biệt lưu ý những hệ thống ngôn ngữ khác không phải
hệ chữ La-tinh sẽ không
được chấp
nhận để đặt tên cho doanh nghiệp
(ví dụ hệ chữ viết mang tính tượng hình tượng thanh như Kana của Nhật, chữ
Hán, chữ Ả Rập...
sẽ không được chấp nhận) (Theo Khoản 1,
2 Điều 39)”. Tên
riêng được viết bằng các chữ cái
trong bảng chữ cái tiếng
Việt, các chữ
F, J, Z, W, chữ số
và ký hiệu.
(Theo Khoản 1, 2, 3 Điều
37).
Mặc dù, 4 chữ nói trên đã
trở thành thông dụng trong tiếng Việt nhưng lại không có trong
bảng chữ cái, khiến cho việc sử dụng chúng trở thành “bất hợp pháp” vì là những
chữ “ngoài luồng”. Đây rõ ràng là
một bất cập của bảng chữ cái hiện hành. Cho nên, việc bổ sung 4 chữ này vào
bảng chữ cái không chỉ
sẽ giải quyết được vấn đề đã nêu mà
nhờ đó tầm phổ quát của bảng chữ cái sẽ được
mở rộng đầy đủ, đáp ứng được sự phát triển của tiếng Việt hiện đại.
Tóm lại, CVNSS 4.0 là chữ viết
không dấu chỉ sử dụng 26 chữ cái Latinh và
trong đó dùng 18 chữ cái Latinh để
thay thế dấu thanh và dấu phụ
cho CQN. Vì nó có biến
đổi linh hoạt giữa các vần chữ
Việt Nam và có sự luân chuyển
giữa các ký diệu dấu,
tạo ra chữ viết có độ chính xác cao
giúp người sử dụng nhận biết được mặt chữ và đọc
được, từ
đây sẽ tạo ra kho
dữ liệu về tên gọi
hoặc các từ ngữ mới làm phong
phú thêm hệ thống câu chữ tiếng
Việt. Ước tính
hiện nay ta có khoảng 36.000 từ ngữ thông dụng thì với CVNSS 4.0 là một cách viết chữ song song với CQN, không ảnh hưởng đến
CQN sẽ tạo nên từ ngữ
gấp đôi.
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/919298829484232/
-------------------
BÀI 15: VŨ
ĐIỆU CỦA NHỮNG CON CHỮ
(ngày 9-1-2023)
Khi bạn bước
vào lớp 1, các bạn nhỏ
(con em chúng ta) sẽ được học và đánh
vần theo
bảng chữ cái với các
chữ được
phát âm như sau: a, bờ, cờ, dờ, đờ (...), gờ, hờ, (...) lờ, mờ, nờ, … Cho đến hết 29 chữ cái trong bảng
chữ cái tiếng Việt. Ta vẫn
gọi đó hệ thống chữ cái chính
thức bảng chữ cái tiếng
Việt (còn gọi tắt là hệ
thống chữ cái ABC).
Tuy nhiên, khi
bạn xem chương trình thời sự hay chương trình bóng đá bạn
sẽ thấy, người dẫn chương trình hay bình luận viên sẽ đọc
khác đi. Ví dụ: nhóm
nước G7, G8, G20... được
các phát thanh viên Đài
truyền hình trung ương (VTV) đọc là “gờ bảy”, “gờ tám”, “gờ hai mươi”
hay như VTV lại đọc tên là “vê tê
vê”. Cụ thể, chữ tắt MC (người dẫn chương trình) ta nghe đọc là “em xi”, sao
không đọc là “Mờ Cờ”
(?)
Đó là vì, hệ
thống tên chữ cái tiếng
Việt của chúng
ta hiện này tồn tại 3 hệ thống bao gồm:
1/ Hệ thống
“a-bờ-cờ”, đây là hệ
thống do lịch sử để lại và tồn
tại từ phong trào bình
dân học vụ sau Cách
mạng T8/ 1945 để
dạy và cấp tốc đẩy lùi “giặc dốt” qua các lớp học
“i tờ”
2/ Hệ thống
“a-bê-xê” còn hệ thống
này vẫn dùng do tên chữ
theo bảng chữ cái cũ
được giám mục Alexandre de Rhodes xác
lập (hệ thống “a-bê-xê”) đặc biệt sự hiện diện của người Pháp trên lãnh thổ
chúng ta một thời gian dài nên đã
ăn sâu vào tiềm thức người dân.
3/ Hệ thống
tên chữ cái tiếng Anh (“ây-bi-xi”), sau này khi chúng
ta hội nhập thì sự xâm
nhập của tiếng Anh của giới trẻ làm cho hệ
thống chữ cái tiếng Việt bị “Anh hóa”, nói khác đi
có khi một
câu tiếng Việt chiếm đến 30% là tiếng Anh.
Vậy làm cách nào
để bảng chữ cái tiếng
Việt chỉ còn một hệ thống tên chữ cái duy
nhất áp dụng ở mọi lúc mọi nơi?
(i) Khi ta dùng hệ thống tên chữ để sử dụng khi đọc từng chữ cái riêng
biệt ta dùng hệ thống
“a-bê-xê”;
(ii) Khi ta dùng hệ thống âm của các chữ dùng
để ghép vần, ta dùng hệ thống “a-bờ- cờ”;
(iii) Còn hệ
thống tên chữ cái tiếng
Anh (“ây-bi-xi”) dùng khi nào bạn
thích, kiểu như Vietlish cho sang, cho có
vẻ bạn là người sính ngoại vậy.
Tới đây, ta lại phát sinh thêm
một vấn đề vậy khi nào có
sự khác nhau giữa âm và tên
chữ cái?
Ta lấy ví
dụ: chữ /r/ cách đọc [rờ] tuy nhiên
cả ba miền Bắc Trung Nam điều
đọc khác nhau. {dộn dàng}, {gộn gàng}, {rộn ràng} …
Qua đây, cho
chúng ta thấy rằng, không có nơi nào
nói đúng hay chuẩn hoàn toàn nhưng chúng ta vẫn có thể giao
tiếp bình thường dựa trên câu chữ.
Bản chất vấn đề nằm ở cách viết và ngữ
nghĩa như thế nào? Trong môi trường nào, phục vụ cho mục
đích gì?
Bản thân bảng chữ cái tiếng
Việt vẫn tồn
tại 3 hệ thống cách đọc khác nhau, bởi chúng ta bị nhầm tưởng là cách đọc
theo chữ, nên phát âm
phải theo chữ vô tình
ta coi một chữ chỉ có một cách
phát âm. Trong ngôn ngữ học thì một
chữ sẽ có nhiều cách phát âm
đó chính là phương ngữ hoặc có những chữ có cách
phát âm giống
nhau nhưng cách viết khác nhau ...
Chữ VN
song song 4.0 (CVNSS4.0) nhóm
tác giả đã khẳng định là không thay thế,
cải tiến mà chỉ là
“song song” với Chữ Quốc Ngữ. Vì sao ta không
chịu chú ý vào phương pháp CVNSS4.0 mà chú ý vào nội
dung bị thay đổi bởi vũ điệu của những con chữ (?)
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/920597949354320/
-------------------
BÀI 16: CHỮ VN SONG SONG 4.0 TỪ ‘PHÁT KIẾN” ĐẾN SỰ
HÌNH THÀNH GIẢ THUYẾT CHO BỘ CHỮ BILA
(ngày 22-3-2023)
Bộ chữ mới Bila này được đặt theo tên hai đồng
tác giả Trần Tư Bình và Kiều Trường Lâm. “Bila” ghép từ 2 chữ cái đầu
tiên của chữ Bình và Lâm. Sau hơn 40 năm nghiên cứu về vấn đề cải tiến chữ Việt, hai tác giả
đã phát kiến ra bộ
chữ Chữ VN Song
Song 4.0 (CVNSS4.0) [1] [2] [3] được
công nhận bản quyền số 1850/2020/QTG.
Để ghi nhận sự đóng góp của họ,
chúng tôi gọi bộ chữ CVNSS4.0 là “bộ chữ Bila”, tên tiếng Anh Bila Script
Language (BSL) trong môi trường máy tính.
Xét về
tính quyết định tương đối của ngôn ngữ chúng tôi cho
rằng: ngôn ngữ chúng ta dùng sẽ ảnh
hưởng đến
cách chúng ta nghĩ, cách chúng ta quyết định một cách mặc định.
Khi “hình thức
chữ viết” của một ngôn ngữ “mẹ đẻ” bị thay đổi
về cách biểu hiện bên ngoài thì
sẽ xuất hiện những suy nghĩ định
kiến trái chiều, không chấp nhận của cộng đồng nói ngôn ngữ đó.
Ngôn ngữ
không tự nhiên sinh ra
mà nó là
một sản phẩm của tư duy con người trong hoàn cảnh cụ thể, môi trường cụ thể cho từng mục đích nhất định. Mỗi ngôn ngữ được tạo dựng để phù hợp để thích ứng với một nền văn hóa riêng nhằm
truyền tải được “phần hồn của tiếng mẹ đẻ” trong các môi trường
vật lý lẫn phi vật lý, lớp vỏ
bọc ngôn ngữ chỉ là hình thức
biểu hiện bên ngoài. Điều
này, giúp chúng tôi nghiên
cứu để củng cố và hoàn thiện
“Giả thuyết về sự phản kháng ngôn ngữ Bila”.
Nếu giả thuyết này phù hợp
sẽ kiểm định được
sự phản kháng thông qua Chữ Quốc Ngữ để đánh giá mức độ
sàn sàng của mỗi cá nhân khi
tham gia vào không gian
mạng. Điều
đó, có nghĩa khi quyền riêng tư càng cao,
tính phản kháng chấp nhận bảo toàn tính riêng
tư được
quan tâm nhiều vì nó liên quan
đến việc lưu trữ, hiển thị và cung cấp
cho bên thứ
ba thông tin liên quan đến
bản thân thông qua Internet.
Điểm nhấn của ngôn ngữ Bila này, nó là
phương tiện
truyền tải thông tin phi tập trung, nghĩa là người nhắn tin lẫn nhận tin không còn phải phụ thuộc hay đặt niềm tin vào bất kỳ
tổ chức trung gian nào
để kiểm soát dữ liệu,
nội dung mà họ trao đổi,
mà thay vào
đó họ có thể trực
tiếp giao dịch trực tiếp với nhau thông qua Cvnss4.0 (ngôn ngữ Bila), không sợ bị bên thứ
ba nắm giữ và sao
chụp nếu họ không biết và học
Cvnss4.0 ngay từ đầu. Từ nền tảng ý tưởng này, giúp chúng ta có
thể tạo ra nhiều ứng dụng công nghệ nhằm mã hóa
các giao dịch từ không gian mạng
ra môi trường
vật lý thực tế.
Có thể
thấy, ảnh hưởng của ngôn ngữ Bila sẽ tác động
đến cách hành xử của
chúng ta khi ta tiếp cận thế giới trên không gian
mạng. Điều
này cũng giống như đặc điểm của phương tiện giao thông sẽ có ảnh hưởng
quyết định
đến cách thức chúng ta tham gia giao
thông, chứ không nhất thiết phải ảnh hưởng đến bản thân đối tượng hay địa
điểm mà chúng ta muốn tiếp cận như thế nào. Ngôn ngữ
Bila, nó vẫn là sự phản
kháng đối với ai không hiểu về Cvnss4.0 nhưng tương lai nó sẽ
thành một quy tắc chung
trong sự giao tiếp để bảo vệ riêng tư của mỗi cá nhân
trên không gian mạng.
Tham khảo:
[1] https://chuvietnhanh.sourceforge.net/ChuVietNhanhKieuChuVietCucNgan.htm
[2] https://tinhte.vn/thread/co-duyen-nao-chu-vn-song-song-4-0-ra-doi-cach-day-vai-thang.3111004
[3] https://chuvietnhanh.sourceforge.net/CongThucChuVNSongSong4.0VaViDu.htm
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/965641364849978/
-------------------
BÀI 17: GIÁ TRỊ TIẾNG
VIỆT QUA CÁC MINH CHỨNG NGHIÊN CỨU. THÊM GÓC NHÌN TỪ CHỮ
VN SONG SONG 4.0
(ngày 7-4-2023)
Chúng ta luôn
bị giới hạn bởi việc não bộ trong tiếp nhận và xử lý
thông tin nhanh, nhưng không bị giới hạn việc xử lý thông
tin bằng khả năng nghe. Điều này, có liên quan
đến sự phát triển sinh học của bộ não và khả
năng tiếp nhận của não bộ thông
qua thông tin lời nói. Dù ta có
nói nhanh hay chậm thì cũng đều có tốc độ
truyền dữ liệu nhanh nhất khoảng 39,15
bit/s (cao gấp 2 lần của mã Morse). Mặt khác, Tiếng Việt ta có mật độ
thông tin cao nhất trong 17 ngôn ngữ điều này rất thú vị
cho sự phát triển của Chữ VN Song Song 4.0 (CVNSS4.0) trong tương lai. Bài phân tích
dưới đây sẽ làm rõ
2 luận điểm
này:
1. Tốc độ truyền dữ liệu nhanh nhất
Nghiên cứu của nhóm Coupé et al., (2019) đã
thực hiện nghiên cứu, tiếng Việt xếp
đầu bảng với 8 bit cho mỗi âm
tiết trong bảng xếp hạng của 17 ngôn ngữ được phân tích (hình 1).
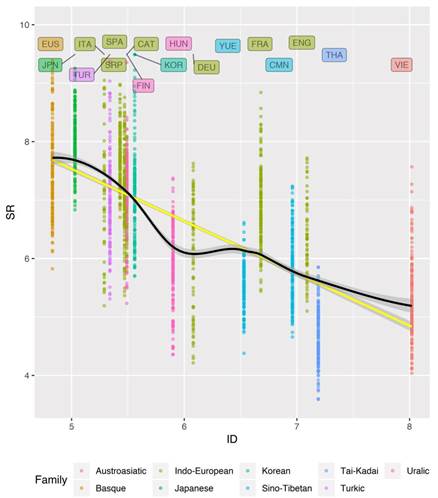
Hình 1. Tiếng Việt xếp đầu trong bảng xếp hạng 17 ngôn ngữ với 8 bit cho mỗi
âm tiết.
Theo:
Coupé, C., Oh, Y. M., Dediu, D., & Pellegrino, F. (2019). Different languages,
similar encoding efficiency: Comparable information rates across the human
communicative niche. Science advances, 5(9), eaaw2594. https://doi.org/10.1126/sciadv.aaw2594
Trong khi đó,
tiếng Nhật, với
chỉ 643 âm tiết, có mật độ thông tin chỉ khoảng 5 bit cho mỗi âm
tiết, và tiếng Anh, với 6.949 âm tiết, có mật độ
thông tin chỉ hơn 7 bit cho mỗi âm tiết.
Tiếng Việt dùng
6 dấu âm, cho phép ta nén
thông tin cao nhất (so với Anh, Nhật,
Nga...). Do mỗi âm tiết tiếng Việt
chứa 8 bit thông tin, điều này đồng nghĩa với việc tiếng Việt
truyền tải thông tin gấp đôi so với tiếng Nhật, và chỉ cần nói với nửa
tốc độ của tiếng Nhật thì vẫn đạt
được tương
đương thông
tin.
Và cũng
là ngoại ngữ khó học
nhất do các thanh dấu tạo nên! Ví dụ: chỉ
cần đổi dấu... Dưa, Dứa, Dừa, Dữa, Dửa, Dựa là thông
tin thay đổi hoàn toàn. Trong khi đó, CVNSS4.0 trên môi trường
máy tính sẽ là Zuao,
Zuax, Zuak, Zuaw, Zuav, Zuah
sẽ không tốn nhiều Bit, như vậy giúp cho việc
truyền dữ liệu là tối
ưu nhất.
Ví dụ
kế tiếp: Tiếng Việt chỉ cần 1 âm tiết "chào", tiếng Anh do đa âm tiết sẽ
là "hê-lô"
(hello). Do đó mà để diễn đạt cùng 1 ý tứ nào đó
tiếng Việt nghe
rất ngắn gọn, súc tích, còn tiếng
Anh sẽ nghe rất dài.
2. Mật độ thông tin cao nhất
Nghiên cứu của nhóm Pellegrino et al., (2011) đã
thực hiện trên 7 ngôn ngữ
khác nhau, bao gồm Anh, Đức, Pháp, Ý, Nhật, Quan Thoại (Trung Quốc), và
Tây Ban Nha với
tiếng Việt được
chọn làm điểm tham chiếu để so sánh với nhau. Kết quả cho thấy
tiếng Việt có mật độ (độ nén) thông tin cao nhất,
đạt giá trị là 1, trong khi các
ngôn ngữ khác đều có mật độ
thông tin thấp hơn, dưới 2 (hình 2).
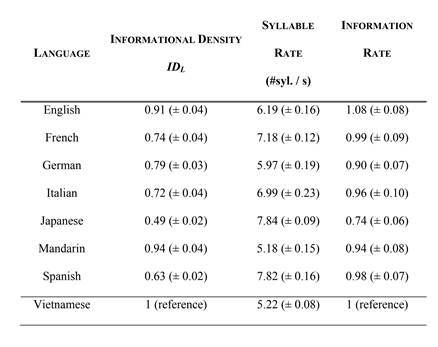
Hình 2. Tiếng Việt có mật độ thông tin cao nhất
trong 8 ngôn ngữ trong nghiên cứu.
Theo:
Pellegrino, F., Coupé, C., & Marsico, E. (2011). Across-Language
Perspective on Speech Information Rate. Language, 87, 539 - 558.
Các ngôn ngữ
gần nhất về mật độ thông tin so với tiếng Việt là tiếng Anh và tiếng Quan Thoại. Điều đó, nghĩa là Tiếng Việt ngôn ngữ giàu thông tin với 1 âm tiết chứa 8 bit thông tin, trong khi tiếng
Anh thì 1 âm tiết chỉ có 7 bit thông tin, còn tiếng Nhật với 1 âm tiết chỉ có 5 bit thông tin. Việc giữ được hồn của tiếng Việt với 6 thanh điệu trong môi trường máy tính, chứa
được nhiều
thông tin, cho thấy CVNSS4.0 đã hữu dụng.
3. Ứng dụng CVNSS4.0
Các nghiên cứu
này là một
phát hiện thú vị, giúp
chúng ta hiểu thêm về đặc
điểm của tiếng Việt. Thông tin này
cũng phần nào thể hiện
được tính cô đọng, đơn giản của tiếng Việt,
với khả năng truyền tải thông tin cao và số
lượng từ cần thiết để truyền tải ý nghĩa là ít. CVNSS4.0 với nền tảng Chữ Quốc Ngữ trong sự phát kiến
của nhóm tác giả Trần
Tư Bình và Kiều
Trường Lâm (2020), đã tận dụng tính hiệu quả để tăng tốc độ xử lý nhằm truyền
tải thông tin cao nhất trong mỗi âm tiết. Điều này giúp cho khả
năng tư duy phát triển
của người nói tiếng Việt, trong đó khả
năng tư duy có thể
giúp rút ngắn và truyền
tải thông tin một cách hiệu quả.
4. Kết luận mở
CVNSS4.0 là kiểu
viết ngắn gọn để diễn ngôn cho tiếng Việt trong môi trường
số, không dấu và dấu
thanh, chỉ dùng 26 chữ cái bảng chữ cái Latinh
để mã hóa thông tin hiệu
quả. Tiếng Việt
là ngôn ngữ
dân tộc Việt có từ thời
Hùng Vương, vượt qua 1000 năm Bắc thuộc, phát triển đến ngôn ngữ cô đọng
ngày nay. Dẫu trải qua nhiều giai đoạn lịch sử thăng trầm, qua nhiều hệ thống các ký hiệu để
ghi lại ngôn ngữ khác nhau. Song Tiếng Việt là tinh hoa, là
bản sắc và linh hồn
của văn hóa Việt, giúp dân tộc đứng
vững và mãi mãi sau
này. Nghiên cứu các phương
thức để phát huy các
giá trị tiếng Việt là nhắc nhở để hiểu và giữ gìn
di sản to lớn này, góp phần
làm giàu, phong phú ngôn
ngữ của dân tộc khẳng
định sức mạnh trên mọi môi trường.
-------
Note: ***Chương trình dự án Chữ VN Song Song 4.0 (CVNSS4.0) là do một nhóm tác giả người
Việt yêu thích ngôn ngữ tiếng Việt, tạo
lập một cộng đồng phi lợi nhuận xuyên quốc gia, nhằm thể hiện vai trò con người
trong biểu đạt thông tin trên môi trường
số thông qua việc khởi tạo và triển
khai ngôn ngữ Bila máy tính trên nền
tảng CVNSS4.0 để
bảo mật riêng tư, ẩn danh, phi tập trung trong lưu trữ. Chương trình này hiện
phát triển trên các ứng
dụng mã nguồn mở và miễn phí,
kết hợp tính khả dụng của Chữ Quốc Ngữ và tính không
giới hạn của tiếng Việt,
nhằm lan tỏa hiểu biết khoa học về ngôn ngữ
với máy tính để bảo tồn tiếng nói, văn hóa Việt Nam trên không gian
số.
5. Tài liệu tham khảo
- Coupé, C., Oh, Y. M., Dediu, D., & Pellegrino, F.
(2019). Different languages, similar encoding efficiency: Comparable
information rates across the human communicative niche. Science advances, 5(9),
eaaw2594. Link <https://www.science.org/doi/10.1126/sciadv.aaw2594>
- Kieu-Tuong Lam, & Tran-Tu Binh. (2020). Typing
CVNSS4.0 with EVKEY is a quick way to type Vietnamese characters on a computer
(1.0). Zenodo. https://doi.org/10.5281/zenodo.7077573
- Pellegrino, F., Coupé, C., & Marsico, E. (2011).
Across-Language Perspective on Speech Information Rate. Language, 87, 539 -
558. Link < https://www.jstor.org/stable/23011654>
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/974308747316573/
-------------------
BÀI 18: CHỮ VIỆT CỔ
QUA LĂNG KÍNH CHỮ VN SONG SONG 4.0
(ngày 7-5-2023)
(Xin tặng file sách dành cho
quý vị)
-------------------
Trong nhiều năm
qua có nhiều nhà nghiên cứu
đã đi theo tiếng gọi quay về nơi viễn cổ thời Hùng
Vương để nhặt
cóp những vết tích đã phai mòn
theo thời gian bằng tình yêu và
lòng tự tôn dân tộc,
nhằm phục dựng lại những con chữ của “người Việt
cổ” từ hàng ngàn năm
trước. Liệu rằng,
tình yêu dân tộc ấy
và những nỗ lực không mệt mỏi dành cho ngôn ngữ,
văn hóa, lịch sử có thay thế
được tính
khoa học hay không
(?) Bài viết dưới đây, sẽ làm rõ
hơn:
Các nhà nghiên
cứu dựa vào cứ liệu
khảo cổ, thư tịch cổ, kết hợp với điền dã cũng chỉ để chứng minh rằng:
(i) Chữ
Việt cổ là một thành tựu rực rỡ của văn minh thời
Hùng Vương, mà không
phải “ngụy trang” bằng vỏ bọc bên ngoài dưới
nhiều hình thức khác nhau, với tên gọi là
“chữ khoa đẩu”. Cha đẻ của bộ sưu tập “chữ Việt cổ” được khởi xướng là nhà nghiên cứu
Đỗ Văn Xuyền
cùng sự ủng hộ của các nhà
nghiên cứu khác với một niềm tin như thế. [Dowload tài liệu]
https://chuvietnhanh.sourceforge.net/CuocHanhTrinhDiTimChuVietCo.pdf
(ii) Nhìn vào
hệ thống tư liệu, cách làm việc,
thời gian nghiên cứu, cũng như nhiệt huyết của tác giả
Đỗ Văn Xuyền,
có thể đây là một
nghiên cứu công phu và
có tính liên
ngành, đặc biệt tác giả sử dụng tư liệu khảo cổ kết hợp với văn tự cổ và thư
tịch cổ mà ngày nay chúng
ta rất trân trọng.
Tuy nhiên, với
luận thuyết và phương pháp tạo ra CVNSS4.0 đã được nghiên cứu và bị
phản biện rất nhiều lần, chúng tôi cho rằng
“chữ khoa đẩu”
rất mong manh về mặt khoa học bởi:
- Nhóm tác
giả chữ việt cổ dùng các ký
tự rất mờ nhạt để so sánh với chữ viết trên bãi đá cổ
Sapa và dùng các luận điểm chủ quan về nền
minh văn trên trống đồng, để xác lập được
bảng chữ cái chữ Việt cổ dùng để
ghi tiếng Việt của người Việt
cổ. Bởi không thể nào từ xa
xưa hơn 2000 năm trước mà bảng chữ
cái lại có đầy đủ số lượng phụ âm và nguyên
âm cơ bản như Chữ Quốc Ngữ nhưng không có dấu thanh.
Bởi Chữ Quốc
Ngữ và chữ Việt cổ do ông giải mã có cùng
cấu trúc ghép vần tương tự nhau, chỉ khác nhau về
hình dạng.
- Dựa vào
tài liệu “Chữ Thái tổ tự” của Phạm Thận Duật (Tri châu Điện Biên năm 1855) và các chữ
viết trong “Thanh Hóa quan phong”
của Vương Duy Trinh (1903), chúng tôi hoài
nghi làm sao có sự
giống nhau về bộ chữ Thái Cổ hay do chính tác giả
tạo ra trong thế kỷ XXI để mọi người tin rằng đó chính là chữ
Việt cổ đã
tồn tại cách nay hơn 2 ngàn năm (?);
Hệ thống chữ viết CVNSS4.0 khi nghiên cứu đã được kiểm tra với ký tự
của một dân tộc, tuân thủ các quy tắc,
đó là: (i) Có khả
năng ghi lại được đầy đủ tiếng nói của dân tộc
nào đó hay không? (ii) Thông qua, các đặc điểm của ký tự
thể hiện được đặc
điểm của ngôn ngữ dân tộc; (iii) Có khả năng
ghi lại các sử kiện
bằng phương
pháp truyền khẩu dân gian. Do vậy, hành trình việc
tìm ra và
giải mã được chữ Việt
cổ rất đáng trân trọng, ghi nhận bởi sáng tạo là quá trình
không chỉ gian khổ mà còn khắc
khổ. Phải có cứ liệu
khoa học và sẵn sàng nhận lấy sự thẩm định, phản biện, thậm chí phê phán
khắc khe của những người khác.
Long Ngo
Nguồn: https://www.facebook.com/groups/toiyeuchuviet4.0/posts/990535169027264/
-------------------
BÀI 19: MẠN ĐÀM VỀ
THANH ĐIỆU TRONG TIẾNG VIỆT TỪ QUÁ KHỨ
ĐẾN TƯƠNG LAI
(ngày 13-5-2023)
Chuyển đổi từ ngôn ngữ chưa có thanh
điệu sang 06 thanh
điệu (?)
“rất khó mà nói
rằng một cách phát âm
hiện nay từ đâu mà ra,
sau hàng mấy trăm năm”. Một trong những nguyên tắc làm việc
cơ bản của ngành ngôn ngữ học lịch sử là Uniformitarian
Principle (UP). Nguyên tắc này
áp dụng ở mọi mặt khi nghiên cứu
đó là xem “hiện tại là chìa
khóa của quá khứ”. Đây
chính là lý do dùng Chữ
VN Song Song 4.0 (CVNSS4.0) với
các lý thuyết
và phương pháp đã bị
mổ xẻ để tìm lại các nhiều
vấn đề trong quá khứ,
chứ không chỉ đơn giản là một
công cụ để mã hóa.
Đầu tiên, giả thuyết về “nguồn gốc của thanh điệu” của
tiếng Việt hiện
nay? Bằng hai bài báo năm
1953 và năm 1954 của nhà ngôn
ngữ học, nhân chủng và địa lý người Pháp rất lỗi lạc đó André-Georges Haudricourt đã dập tắt những tranh luận và nghi
ngờ trước đây của các học giả
Việt Nam, bị thuyết
phục và ngày nay được phần lớn các nhà ngôn
ngữ học chấp nhận nguồn gốc của thanh điệu xuất phát từ Mon-Khmer khi nói đến
tiếng Việt và việc xếp tiếng Việt vào dòng họ ngôn
ngữ Nam Á mà chúng ta chấp nhập đến ngày nay của đến từ kiến giải. Ông đã chứng
minh rằng tiếng Việt thuộc
cùng họ với các ngôn
ngữ Mon-Khmer là những tiếng
không có thanh điệu. Chính các tác
giả hiện nay điều nhất trí trong quan
niệm này đựa dựa trên luận điểm của Haudricourt, tin rằng tiếng Việt thuộc
họ Nam Á, nhánh
Mon-Khmer, chi Việt- Mường (!).
Như vậy, lịch sử hình thành thanh
điệu của tiếng Việt là từ không có thanh điệu
đến có sáu thanh điệu
như hiện nay thế nào?. Tiếng Việt hiện đại là một ngôn
ngữ có thanh điệu, điều này cho thấy trong quá trình
lịch sử của mình, tiếng Việt đã
biến đổi khá xa so với các ngôn
ngữ Môn-Khmer cùng gốc ban đầu. Đây là một
vấn đề còn bỏ ngỏ
cần được
quan tâm nhiều hơn thêm khi có
đầy đủ
tư liệu hơn.
(i) Từ
không thanh điệu thành có thanh điệu,
vấn đề không chỉ nằm ở hình thức và trong
chính bộ máy phát âm
của con người
đã có khả năng rất kỳ diệu để tạo ra nhiều
âm thanh khác nhau, nhờ
áp dụng các biện pháp ngữ âm phong phú
này.
(ii) Việc chúng ta tin rằng tiếng Việt thuộc
họ Nam Á, nhánh
Mon-Khmer, nhưng chưa
bao giờ chúng ta có sự so sánh ngôn ngữ
tiếng Việt với
tiếng Môn liệu rằng có thiếu
sót hay không? Chúng tôi tin rằng,
chữ Việt cổ
có thể là một hệ
chữ viết cổ có nguồn
gốc xuất phát từ chữ
Brahmi và tồn tại trên các ký hiệu
trong văn hóa Đông Sơn, dĩ nhiên cần phải kiểm chứng nhiều hơn.
(iii) Nếu như ngữ điệu là đặc trưng của câu, trọng âm là đặc trưng của từ thì thanh
điệu là đặc trưng của âm tiết.
Với 6 thanh tiếng Việt: ngang, huyền, hỏi, ngã, sắc, nặng. Thanh được
thể hiện trên chữ viết là dấu
thanh (còn gọi là dấu).
Và thanh điệu chính là sức mạnh,
là đặc trưng quan trọng của tiếng Việt. Trong công
thức CVNSS4.0 chúng tôi chỉ thay
“ký hiệu dấu” bằng chữ chữ cái, điều này không vi phạm
quy tắc gõ dấu mà
còn gia tăng
hiệu suất trong môi trường
máy tính khi thể hiện
văn phong tiếng Việt.
Từ thanh điệu sang ngữ điệu bị phương ngữ hóa
* Phương ngữ miền Bắc: Đầy
đủ 6 thanh điệu của tiếng Việt. Nhiều
địa phương
không có các âm vị
phụ âm đầu /ʂ/, /ʈ/, /z/, /z̪/ (chính tả là s, tr, gi và
r), tức là không phân biệt
s/x, tr/ch, d/gi/r. Ngoài ra còn
lẫn lộn phụ âm /l/ và /n/ (l và n). Phân biệt rõ ràng /v/ và
/z/ (v và d). Không phân biệt các vần được
thể hiện trong chính tả
là ưu/iu và ươu/iêu. Đầy đủ phụ âm cuối.
* Phương ngữ miền
Trung: Gồm 5 thanh, thanh hỏi và thanh ngã
bị lẫn lộn. Phụ âm đầu có 3 phụ âm uốn lưỡi
/ş/, /z̪/, // (tức s, r, tr). Nhiều thổ ngữ có 2 phụ âm bật
hơi [ph, kh] thay cho
phụ âm /f/, /χ/
(ph và kh)
ở phương ngữ
Bắc. Hệ thống
nguyên âm đôi bị đơn hóa, trong chính tả
ươ thành ư và uô thành
u. Phụ âm cuối, từ Thừa Thiên Huế đổ vào, có sự biến
đổi /-n/ sang /-ŋ/ (n sang ng) và /-t/ sang /-k/ (t sang c).
* Phương ngữ miền
Nam: Thanh điệu gồm
5 thanh, thanh hỏi và ngã
trùng làm một. Có các
phụ âm uốn lưỡi
/ş, /z̪/, / (s, r, tr). Thiếu phụ âm /v/, nhưng lại có thêm âm
[w]; âm [j] thay thế cho /z/. Âm đệm /-w-/ dần biến mất. Ví dụ:
“rốt cuộc” biến thành “rốt cục”. Đồng nhất các vần tương đương trong chính tả là “in” với “inh”, “it” với
“ich”, “un” với “ung”,
“ut” với “uc”. m “iêu” thành “iu”, “oai” thành
“ai”.
(i) Mặc
dù, thanh điệu là đặc trưng quan trọng của tiếng Việt,
nhưng đến từng địa phương, vùng miền đã bị địa phương hóa, điều đó sẽ tác động
đến ngữ điệu riêng mang tính đặc
thù. Nhưng khi thể hiện
trên cùng một văn bản nhất là máy tính
ta cần phải có tính nhất
chung. Việc này không đơn
giản bởi xử lý ngôn
ngữ tiếng Việt
rất khó khăn, hiện nay có nhiều giải pháp và CVNSS4.0 cũng là một trong
những giải pháp mang tính
gợi mở để các chuyên gia ngôn
ngữ và lập trình viên máy tính
cùng ngồi lại với nhau.
(ii) Với nhiều cứ liệu thực nghiệm, các nghiên cứu này đã chỉ
ra rằng vai trò của
ngữ điệu trong các ngôn
ngữ có thanh điệu sẽ bị hạn chế rất nhiều so với ngữ điệu trong các ngôn ngữ
không có thanh điệu. Nhận định này đã từng
được nêu lên trước đây nhưng đã không được
chứng minh. Nhưng có lẽ,
khi xử lý tiếng Việt trên máy tính
đã cho thấy điều đó.
Từ thanh điệu đến sự nhập nhằng trong xử lý tiếng Việt
Trong xu thế công nghệ 4.0 và phát triển
mạnh mẽ của AI, văn hóa Việt Nam phải được khẳng định ngay cả trên không
gian mạng trong đó có
tiếng Việt nên có những thay đổi và phát triển
không ngừng, CVNSS4.0
ra đời là để hội nhập cho xu thế trên. Chính sự
đa dạng, phong phú trong
cách tư duy của người
Việt, cách vận dụng đã tạo nên những
đặc điểm
гất riêng mà гất ít ngôn ngữ
của dân tộc nào trên
thế giới có được. CVNSS4.0
nhằm khắc phục các nhược điểm đó để xử lý tiếng
Việt trở nên tối ưu hơn. Một trong những hiện tượng tạo ra sự
“phức tạp và rắc rối”
của tiếng Việt
chính là “hiện tượng nhập nhằng” như phân tích
ở trên, đó là hiện tượng
mà khi nói
hoặc viết những từ ngữ mơ hồ không rõ nghĩa hoặc
có nhiều nghĩa làm cho người đọc hoặc người nghe không phân biệt
rõ ràng, gây ra sự
hiểu lầm.
CVNSS4.0 với tương lai về mô hình
chatbot tiếng Việt phải
được triển
khai trên servers, trên cơ cở
hạ tầng do chính các tập
đoàn/công ty lớn/tổ chức người Việt
bảo mật và kiểm soát.
Trong trường hợp
này liệu OpenAI làm không, chắc
chắn là làm được nhưng họ sẽ không làm bởi yếu
tố nước ngoài! Mô hình
ngôn ngữ lớn tiếng Việt với vỏ bọc bảo mật CVNSS4.0 nếu tiếp theo được xây dựng trên LLaMA chẳng hạn có độ
tốt 90% so với
ChatGPT sẽ bao gồm
tiếng Việt, tiếng
Anh và các ngôn ngữ lập trình khác cũng đã tốt rồi. Vậy CVNSS4.0 sẽ có tiềm
năng lớn khi tham gia
vào mô hình
ngôn ngữ lớn tiếng Việt được xây dựng cho riêng mình, trong
lĩnh vực nào đó như
hình thành chữ viết riêng cho các
dân tộc thiểu số chưa có chữ
viết, với khoảng 50 tỉ tham số (bằng 1/6 so với GPT-3
của OpenAI) là cũng đã thành công rồi.
Tài liệu tham khảo:
- De
l’origine des tons en vietnamien, Journal Asiatique
242: 69-82 (1954). Reprinted in Problèmes de phonologie diachronique:
146-160.
- La
place du vietnamien dans les langues
austroasiatiques, Bulletin de la Société de Linguistique de Paris 49(1): 122– 128.
- Mai,
L. C. (2005) & Bảo, H. T. Về xử lý tiếng Việt trong
công nghệ thông tin.
Long Ngo
+
NGUỒN: 19 BÀI VỀ CHỮ VIỆT
THỜI CÔNG NGHỆ SỐ
https://www.facebook.com/groups/toiyeuchuviet4.0/user/1263501219
+
Ghi chú: Long Ngo (Ngô Hoàng Đại Long) hiện đang là Nghiên
cứu viên tại Phân hiệu Đại học Quốc gia-TP.HCM tại tỉnh Bến Tre, có nhiều công trình khoa học – được công bố trên Scopus & WoS – liên quan
đến hướng
nghiên cứu của mình về Địa lý ngôn ngữ,
nhất là các Ứng dụng
của xử lý ngôn ngữ
tự nhiên (Natural
Language Processing – NLP) trong GIScience.
(Facebook: Long Ngo https://www.facebook.com/dailong0606, Email:
ngohoangdailong@gmail.com)
+
19 bài này cũng được đăng ở Phụ Lục trong Giáo trình Chữ
VN Song Song 4.0:
https://chuvietnhanh.sourceforge.net/GiaoTrinhChuVNSongSong.htm
Về Trang Chính: Chữ Việt Nhanh
http://chuvietnhanh.sourceforge.net